与我交流

# 5.2 在 convnet 上通过迁移学习进行目标检测
到目前为止,您在本章中看到的迁移学习的例子有一个共同点:机器学习任务的性质在转移之后保持不变。特别是,他们把一个在多类分类任务上训练过的计算机视觉模型应用到另一个多类分类任务上。在本节中,我们将展示原始模型可以用于非常不同的任务,例如,当您想要使用在分类任务上训练的基本模型来执行回归(即拟合一个数字)时。这种跨域转移是深度学习的多功能性和可重用性的一个很好的例子。
我们将用来解释这一点的新任务是目标检测,这是您在本书中遇到的第一个非分类计算机视觉问题类型。目标检测涉及到检测图像中特定类别的目标。它和分类有什么不同?在目标检测中,检测到的目标不仅按照其类别(它是什么类型的对象)进行报告,而且还报告一些有关对象在图像中的位置(对象在哪里)的附加信息。后者是单纯的分类器所不能提供的信息。例如,在自动驾驶汽车使用的典型目标检测系统中,分析输入图像的帧,以便该系统不仅输出图像中存在的感兴趣对象的类型(例如,车辆和行人),而且还输出这些对象在图像坐标系内的位置、大小和姿态。
示例代码位于 tfjs-examples 库的目录 simple-object-detection 中。请注意,这个示例与您目前看到的示例不同,它将 Node.js 中的模型训练与浏览器中的推理结合在一起。具体来说,模型训练是使用 tfjs-node(或 tfjs-node- gpu)进行的,训练后的模型保存到磁盘。然后使用一个包服务器来保存模型文件,以及静态的 index.html 和 index.js,以便在浏览器中显示对模型的推断。
运行示例时可以使用的命令序列如下(其中包含一些在输入命令时不需要包含的注释字符串):
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/simple-object-detection
yarn
# Optional step for training your own model using Node.js:
yarn train \
--numExamples 20000 \
--initialTransferEpochs 100 \
--fineTuningEpochs 200
yarn watch # Run object-detection inference in the browser.
yarn train 命令在您的机器上执行模型训练,并在完成后将模型保存在./dist 文件夹中。请注意,这是一个长期的训练工作,如果您有一个启用 CUDA 的 GPU,它可以将训练速度提高 3 到 4 倍。要执行此操作,只需将--gpu 标志添加到 yarn train 命令,即。,
yarn train --gpu \
--numExamples 20000 \
--initialTransferEpochs 100 \
--fineTuningEpochs 200
但是,如果您没有时间或资源在自己的机器上训练模型,请不要担心:您可以跳过 yarn train 命令直接执行 yarn watch。在浏览器中运行的推断页面将允许您通过 HTTP 从一个集中的位置加载我们已经为您训练过的模型。
# 5.2.1 基于合成场景的简单目标检测问题
最先进的目标检测技术涉及许多技巧,不适合作为本主题的入门教程。我们在这里的目标是展示目标检测工作的本质,而不是被太多的技术细节所束缚。为此,我们设计了一个涉及合成图像场景的简单目标检测问题(如图 5.14)。这些合成图像的尺寸为 224x224,颜色深度为 3(RGB 通道),因此与构成我们模型基础的 MobileNet 模型的输入规范相匹配。如图 5.14 所示,每个场景都有一个白色背景。要检测的对象是等边三角形或矩形。如果对象是三角形,则其大小和方向是随机的;如果对象是矩形,则其高度和宽度是随机变化的。如果场景仅由白色背景和感兴趣的对象组成,任务将很容易显示我们技术的威力。为了增加任务的难度,在场景中随机散布了一些“噪波对象”。其中包括 10 个圆和 10 条线段。圆的位置和大小是随机生成的,线段的位置和长度也是随机生成的。一些噪波对象可能位于目标对象的顶部,部分遮挡目标对象。所有目标和噪声对象都有随机生成的颜色。
# 图 5.14 简单目标检测使用的合成场景的示例。A:一个旋转的等边三角形作为目标物体。B:一个矩形作为目标对象。标记为“true”的红色框是感兴趣对象的真正边界框。请注意,感兴趣的对象有时会被某些噪波对象(线段和圆)部分遮挡。
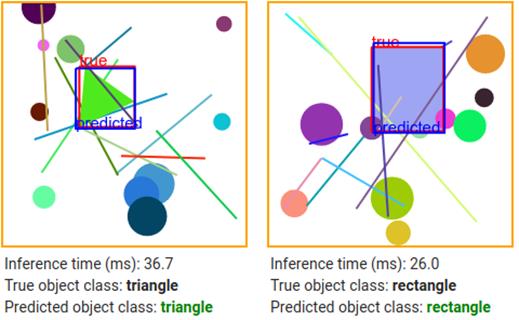
使用合成数据的好处是 1)真正的标签值是自动知道的,2)我们可以生成任意多的数据。每次我们生成场景图像时,对象的类型及其边界框都会从生成过程中自动提供给我们。因此不需要对训练图像进行任何劳动密集型标记。这种非常有效的过程,其中输入特征和标签被合成在一起,在许多用于深度学习模型的测试和原型环境中使用,并且是一种您应该熟悉的技术。然而,用于真实图像输入的训练目标检测模型需要手动标记真实场景。幸运的是,有这样的标记数据集可用,(COCO)数据集[84]就是其中之一。
训练完成后,模型应该能够得到相当好的精度定位和分类的目标对象(如图 5.14 中的示例所示)。要了解模型如何学习这个对象检测任务,请与我们一起深入到下一节的代码中。
# 5.2.2 深入研究简单目标检测
现在让我们建立神经网络来解决综合目标检测问题。如前所述,我们在预先训练的 MobileNet 模型上建立我们的模型,以便在模型的卷积层中使用强大的通用的视觉特征提取器。清单 5.9 中的 loadTruncatedBase() 方法就是这样做的。然而,我们的新模型面临的一个新挑战是如何同时预测两件事:确定目标物体的形状和在图像中找到其坐标。我们以前从未见过这种“双重任务预测”。我们在这里使用的技巧是:让模型输出一个包含两个预测的张量,然后我们将设计一个新的损失函数来测量模型在两个任务中同时执行的情况。我们可以训练两个独立的模型,一个用于形状分类,另一个用于预测边界框。但是,与使用单个模型执行这两个任务相比,运行两个模型将涉及更多的计算和更多的内存使用,并且不利用可以在两个任务之间共享的特征提取层这一事实。
# 清单 5.9 基于截断 MobileNet 定义简单对象学习模型(来自 simple-object-detection/train.js[85])
const topLayerGroupNames = ['conv_pw_9', 'conv_pw_10', 'conv_pw_11']; #A:
const topLayerName =
`${topLayerGroupNames[topLayerGroupNames.length - 1]}_relu`;
async function loadTruncatedBase() {
const mobilenet = await tf.loadLayersModel(
'https://storage.googleapis.com/tfjs-models/tfjs/mobilenet_v1_0.25_224/model.json');
const fineTuningLayers = [];
const layer = mobilenet.getLayer(topLayerName); #B:
const truncatedBase =
tf.model({inputs: mobilenet.inputs, outputs: layer.output}); #C:
for (const layer of truncatedBase.layers) {
layer.trainable = false; #D:
for (const groupName of topLayerGroupNames) {
if (layer.name.indexOf(groupName) === 0) { #E:
fineTuningLayers.push(layer);
break;
}
}
}
return {truncatedBase, fineTuningLayers};
}
function buildNewHead(inputShape) { #F:
const newHead = tf.sequential();
newHead.add(tf.layers.flatten({inputShape}));
newHead.add(tf.layers.dense({units: 200, activation: 'relu'}));
newHead.add(tf.layers.dense({units: 5})); #G:
return newHead;
}
async function buildObjectDetectionModel() {
const {truncatedBase, fineTuningLayers} = await loadTruncatedBase();
const newHead = buildNewHead(truncatedBase.outputs[0].shape.slice(1));
const newOutput = newHead.apply(truncatedBase.outputs[0]);
const model = tf.model({inputs: truncatedBase.inputs, outputs: newOutput}); #H:
return {model, fineTuningLayers};
}
“双重任务”模型的关键部分由清单 5.9 中的 buildNewHead()方法构建。模型示意图如图 5.15 左侧所示。新的头部由三层组成:一个扁平层,它重置了截断的 MobileNet 原始模型最后一个卷积层的输出的形状,以便以后可以添加致密层。第一致密层是一个具有 relu 非线性的隐层。第二致密层是头部的最终输出,因此是整个目标检测模型的最终输出。此层具有默认的线性激活。这是理解该模型如何工作的关键,因此需要仔细研究。
# 图 5.15 目标检测模型及其所基于的自定义丢失函数的示意图。请参见代码清单 5.9 了解如何构造模型(左侧部分),请参见代码清单 5.10 了解如何编写自定义丢失函数。
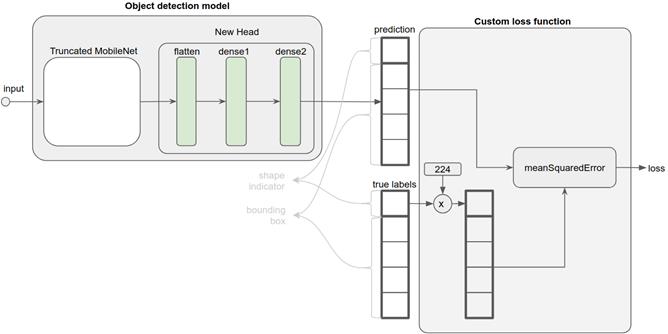
从代码中可以看到,最终密集层的输出单位计数为5。这5个数字代表什么?它结合了形状预测和边缘预测。有趣的是,决定它们意义的不是模型本身,而是用于模型的损失函数。之前,您已经看到了各种类型的损失函数,它们可以是简单的字符串名称,例如“meanSquaredError”,并且适合于它们各自的机器学习任务(例如,请参见第3章中的表3.6)。但是,这只是在TensorFlow.js中指定损失函数的两种方法之一。另一种方法是,定义一个满足特定意义的自定义JavaScript函数。如下: • 两个输入参数:1)输入示例的真标签和2)模型的相应预测。每一个都表示为一个二维张量。两个张量的形状应该相同,每个张量的第一个维度是批量大小。 • 返回值是标量张量(即形状为[]的张量),其值是批处理中示例的平均损失。
根据这个规则编写的自定义丢失函数如清单5.10所示,并在图5.15的右侧部分以图形方式显示。customLossFunction(yTrue)的第一个输入是真正的标签张量,其形状为[batchSize,5]。第二个输入(yPred)是模型的输出预测,其形状与yTrue完全相同。沿第二轴yTrue的五个维度中(即五列,我们将其视为矩阵),第一维度是目标对象形状的0-1指示器(0表示三角形,1表示矩形)。这取决于数据的合成方式(参见simple-object-detection/synthetic_images.js)。其余四列是目标对象的边界框,即其左、右、上和下值,每个值的范围从0到画布大小(224)。数字224是输入图像的高度和宽度,它来自MobileNet的输入图像大小,我们的模型是基于MobileNet的。
loss 函数接受 yTrue 并按画布大小缩放第一列(即 0-1 形状指示器),同时保持其他列不变。然后计算 yPred 与标度 yTrue 之间的均方误差。为什么我们要在 yTrue 中缩放 0-1 形状标签?这是因为我们希望模型输出一个数字,表示它预测的形状是三角形还是矩形。具体地说,对于三角形,它输出一个接近 0 的数字,对于矩形,输出一个接近画布大小(即 224)的数字。因此,在推理过程中,我们只需将模型输出中的第一个值与 CANVAS_SIZE/2(即 112)进行比较,就可以得到模型对形状是更像三角形还是矩形的预测。然后问题是如何测量这种形状预测的精度,从而得出一个损失函数。我们的答案是计算这个数字与 0-1 指标乘以画布大小之间的差。为什么我们要这样做,而不是像第 3 章中的钓鱼检测示例那样使用二进制交叉熵?这是因为我们需要结合两个精度指标:一个用于形状预测,另一个用于边界框预测。后一个任务涉及预测连续值,可以看作是一个回归任务。因此,均方误差是边界框的自然度量。为了组合度量,我们只是“假装”形状预测也是回归任务。这个技巧允许我们使用一个度量函数(即清单 5.10 中的 tf.metric.meanSquaredError()调用)来封装两个预测的损失。
但为什么我们要将 0-1 指标按画布大小比例缩放呢?如果我们不进行这种缩放,我们的模型最终将生成一个 0-1 附近的数字,作为它预测形状是三角形(接近 0)还是矩形(接近 1)的指示器。与我们比较真实边界框和预测边界框(范围在 0 到 224 之间)得到的差异相比,[0,1]区间周围的数字之间的差异显然要小得多。因此,边界盒预测的误差信号将完全掩盖形状预测的误差信号,这将无助于我们获得准确的形状预测。通过缩放 0-1 形状指示器,我们确保形状预测和边界框预测对最终损失值(即 customLossFunction 的返回值)的贡献大致相等,以便在训练模型时,它将同时优化这两种类型的预测。在本章末尾的练习 4 中,我们鼓励您自己进行缩放实验[86]。
# 清单 5.10 为对象检测任务定义自定义丢失函数(来自 simple-object-detection/train.js)
const labelMultiplier = tf.tensor1d([CANVAS_SIZE, 1, 1, 1, 1]);
function customLossFunction(yTrue, yPred) {
return tf.tidy(() => {
return tf.metrics.meanSquaredError(yTrue.mul(labelMultiplier), yPred); #A:
});
}
准备好数据,定义了模型和损失函数,我们就可以训练我们的模型了!模型训练代码的关键部分如清单 5.11 所示。就像我们之前看到的微调(第 5.1.3 节)一样,训练分为两个阶段进行:初始阶段,仅训练新的头层;微调阶段,将新的头层与截断的 MobileNet 基的前几层一起训练。应该再次注意的是,必须在微调 fit()调用之前(再次)调用该 compile()方法,以使对应层属性的更改生效。如果你在自己的机器上进行训练,那么一旦微调阶段开始,很容易观察到损失值的显著下降,反映了模型容量的增加,以及解冻后的特征提取层由于解冻而适应于对象检测数据中的独特特征。微调期间未冻结的层的列表由 fineTuningLayers 数组决定,在我们截断 MobileNet 时填充数组(请参见清单 5.9 中的 loadTruncatedBase 函数)。这是截短的 MobileNet 的前九层。在本章末尾的练习 3 中,您可以尝试解冻较少或更多的基础顶层,并观察它们如何更改由训练过程生成的模型的精度。
# 清单 5.11 训练目标检测模型的第二阶段(来自 simple-object-detection/train.js)
const {model, fineTuningLayers} = await buildObjectDetectionModel();
model.compile({loss: customLossFunction, optimizer: tf.train.rmsprop(5e-3)}); #A:
await model.fit(images, targets, {
epochs: args.initialTransferEpochs,
batchSize: args.batchSize,
validationSplit: args.validationSplit
}); #B:
#Fine-tuning phase of transfer learning.
for (const layer of fineTuningLayers) {
layer.trainable = true; #C:
}
model.compile({loss: customLossFunction, optimizer: tf.train.rmsprop(2e-3)}); #D:
await model.fit(images, targets, {
epochs: args.fineTuningEpochs,
batchSize: args.batchSize / 2, #E:
validationSplit: args.validationSplit
}); #F:
微调结束后,将模型保存到磁盘,然后在浏览器内推断步骤(由 yarn watch 命令启动)中加载。如果加载托管模型,或者已经花费时间和资源在自己的计算机上训练了一个相当好的模型,那么在推断页面中看到的形状和边界框预测应该相当好(初始训练 100 个阶段,精调 200 个阶段后的验证损失小于 100)。推断结果良好,但并不完美(例如,参见图 5.14 中的示例)。在检查结果时,请记住浏览器内评估是一个公平的评估,它反映了模型的真正泛化能力,因为在浏览器中受训的模型要解决的示例不同于它在迁移学习过程中看到的训练和验证示例。
为了总结这一部分,我们展示了如何将先前训练过的图像分类模型成功地应用于另一个任务,即目标检测。在此过程中,我们演示了如何定义一个自定义损失函数来适应对象检测问题的“双重任务”(形状分类+边界回归)性质,以及如何在模型训练期间使用自定义损失。这个例子不仅说明了目标检测背后的基本原理,而且还强调了迁移学习的灵活性和它可能解决的问题。真正应用程序中使用的对象检测模型当然比我们在这里使用合成数据集构建的示例更复杂,涉及更多技巧。下面的信息框 5.3 简要介绍了一些有关高级对象检测的模型,它们与您刚才看到的简单示例有何不同,以及如何通过 TensorFlow.js 使用其中一个模型。
# 信息框 5.3:创建目标检测模型
# 图 5.16 来自 TensorFlow.js 版本的单点检测(SSD)模型的示例对象检测结果。请注意多个边界框及其关联的对象类和置信度分数。

目标检测是图像理解、工业自动化和自动驾驶汽车等许多应用领域感兴趣的重要任务。最著名最先进的目标检测模型包括单镜头检测[87](SSD,其示例推理结果如上图所示)和 YOLO[88](You Only Look Once)。这些模型与我们在简单目标检测示例中看到的模型在以下方面类似:
- 它们可以预测物体的类别和位置
- 它们建立在 MobileNet 和 VGG16[89]等预先训练的图像分类模型上,并通过迁移学习进行训练。 不过,它们在许多方面也不同于我们的示例模型:
- 实际对象检测模型预测的对象类别比我们的简单模型要多得多(例如,COCO 数据集[90]有 80 个对象类别)
- 它们能够检测同一图像中的多个对象(例如,见上图示例)
- 他们的模型架构比我们简单模型中的架构更复杂。例如,SSD 模型在截短的预训练图像模型上添加多个新的头部,以预测输入图像中多个对象的类置信度得分和边界框。
- 真实目标检测模型的损失函数不是使用单个 meanSquaredError 度量作为损失函数,而是两类损失的加权和:a)对象类预测概率得分的 softmax 交叉熵损失,b)边界框的 meanSquaredError 或 meanAbsoluteError。两种损失值之间的相对权重经过仔细调整,以确保两种误差源的贡献均衡。
- 真实目标检测模型为每个输入图像生成大量的候选边界框。这些边界框被“剪除”,以便在最终输出中保留对象类概率得分最高的边界框。
- 一些真实的目标检测模型包含了关于目标边界框位置的先验知识。这些都是基于对大量标记真实图像的分析,对图像中边界框的位置进行有根据的猜测。通过从一个合理的初始状态开始,而不是从完全随机的猜测(如我们的示例中 simple-object-detection 所示)来帮助加快模型的训练。 一些真实物体检测模型已经移植到 TensorFlow.js 中。例如,您可以使用的最佳目录之一是 tfjs-models 库的 coco-ssd 目录。要查看它的运行情况:
git clone https://github.com/tensorflow/tfjs-models.git
cd tfjs-models/coco-ssd/demo
yarn && yarn watch
有兴趣了解更多真实物体检测模型的读者可以阅读以下博客文章。它们分别用于 SSD 模型和 YOLO 模型,它们使用不同的模型体系结构和后处理技术:
- Eddie Forson 的“了解 SSD 多盒-深度学习中的实时目标检测”:https://towardsdatascience.com/Understanding-SSD-MultiBox-Real-Time-Object-Detection-In-Deep-Learning-495ef744fab
- Jonathan Hui 的“YOLO、YOLOv2 和 now YOLOv3 实时目标检测”:https://medium.com/@Jonathan Hui/Real-time-Object-Detection-with-YOLO-YOLOv2-28b1b93e2088
到目前为止,在这本书中,我们处理了机器学习数据集,这些数据集已经交给我们,并准备好进行探索。它们的格式很好,经过我们数据科学家和机器学习研究人员的艰苦工作,我们可以专注于建模,而不必太担心如何摄取数据和数据是否正确。这对于本章中使用的 MNIST 和音频数据集是正确的;对于第 3 章中使用的钓鱼网站和 Iris-flower 数据集也是正确的。
我们可以肯定地说,对于你将遇到的现实世界的机器学习问题来说,情况永远不是这样的。实际上,机器学习从业者的大部分时间都花在获取、预处理、清理、验证和格式化数据上[91]。在下一章中,我们将向您介绍 TensorFlow.js 中提供的工具,使这些数据获取工作流更容易。