与我交流

# 5.1 迁移学习简介:重用预训练模型
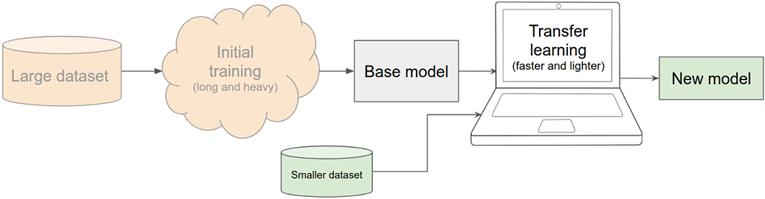
从本质上讲,迁移学习是通过重用先前学习的结果来加速新的学习任务。它涉及到使用已经在数据集上训练过的模型来执行不同但相关的机器学习任务。已训练的模型称为基础模型。迁移学习包括重新训练基础模型,或者在基础模型的基础上创建一个新模型。我们把新模型称为转移模型。如图 5.1 中的示意图所示,与用于训练基本模型的数据(例如,本章开头给出的两个示例)相比,用于此再训练过程的数据量通常要小得多,与基本模型的训练过程相比,迁移学习通常要花费更少的时间和资源。这使得使用 TensorFlow.js 在资源受限的环境(如浏览器)中执行迁移学习成为可能。这使得迁移学习成为 TensorFlow.js 学习者的一个重要课题。
# 图 5.1 显示迁移学习一般工作流程的示意图。数据集大的在基本模型进行训练。这个初始训练过程通常很长,计算量也很大。然后重新训练基本模型,可能成为新模型的一部分。再培训过程通常涉及比原始数据集小得多的数据集。与初始训练相比,再训练所涉及的计算量要少得多,并且可以在(如笔记本电脑或可运行 TensorFlow.js 的手机)上进行。
迁移学习描述中的关键短语“不同但相关”在不同情况下可能意味着不同的事情:
- 本章开头提到的第一个场景涉及根据特定用户的数据调整模型。尽管数据与原始训练集不同,但任务是完全相同的,即将图像分类为 10 位数字。这种类型的迁移学习被称为模型适应。
- 其他的迁移学习问题涉及到不同于原来的目标(标签)。本章开头提到的商品图像分类场景属于该类别。 与从头开始培养新模式相比,迁移学习有什么优势?答案有两个:
- 从所需的数据量和所需的计算量来看,迁移学习更有效
- 建立在先前训练的基础上可以重用基本模型的特征提取能力。
这些点是有效的,与问题的类型无关(例如,分类和回归)。在第一个点上,迁移学习使用来自基本模型(或其子集)的训练权重。因此,与从头开始训练新模型相比,它需要较少的训练数据和训练时间才能收敛到给定的精度水平。在这方面,迁移学习类似于人类学习新任务的方式:一旦掌握了一项任务(例如,玩纸牌游戏),学习类似的任务(例如,玩类似的纸牌游戏)在未来变得更加容易和快捷。对于我们为 MNIST 构建的 convnet 这样的神经网络来说,节省的训练时间成本似乎相对较小。然而,对于在更大数据集上训练的更大模型(例如,在兆字节图像数据上训练的工业级 convnets),可以节省大量成本。
第二点,迁移学习的核心思想是重用先前的训练结果。通过对一个非常大的数据集的学习,原始神经网络能够很好地从原始输入数据中提取有用的特征。只要迁移学习任务中的新数据与原始数据没有太大的差异,这些特性对于新任务是有用的。研究人员已经为常见的机器学习领域组装了非常大的数据集。在计算机视觉中,有 ImageNet[73],它包含来自大约 1000 个类别的数百万个标记图像。深度学习研究人员已经使用 ImageNet 数据集(如 ResNet、Inception 和 MobileNet,我们不久将着手开发最后一个数据集)对深度神经网络进行了训练。由于 ImageNet 中图像的数量和多样性,在其上训练的 convnets 对于一般类型的图像是很好的特征抽取器。这些特征抽取器对于处理像上面提到的场景那样的小数据集很有用,但是对于那些小数据集来说,训练这样有效的特征抽取器是不可能的。迁移学习的机会也存在于其他领域。例如,在自然语言处理中,人们已经在由数十亿个单词组成的大型文本语料库中训练了单词嵌入(即语言中所有常用单词的矢量表示)。这些嵌入对于语言理解任务非常有用,因为可以使用更小的文本数据集。
不用再费心了,让我们通过一个例子来看看迁移学习在实践中是如何工作的。
# 5.1.1 基于兼容输出形状的迁移学习:冻结层
让我们从一个相对简单的例子开始。我们首先在 MNIST 数据集的前五位(0 到 4)上训练 convnet。然后,我们将使用生成的模型来识别剩余的 5 位数字(5 到 9),这是模型在原始训练中从未见过的。虽然这个例子有些做作,但它说明了迁移学习的基本工作流程。举出示例并使用以下命令行运行:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/mnist-transfer-cnn
yarn && yarn watch
在打开的演示网页中,单击“retrain”按钮启动迁移学习过程。你可以看到这个过程在新的五位数(5-9)上达到了 96%的精确度,在一台功能相当强大的笔记本电脑上大约需要 30 秒。正如我们将要展示的,这比非迁移学习的替代方法(即从头开始训练新模型)要快得多。让我们一步一步来看看是怎么做到的。
我们的示例从 HTTP 服务器加载预训练的基本模型,而不是从头开始训练它,以免模糊工作流的关键部分。回想第 4.3.3 节,TensorFlow.js 提供了加载预训练模型的方法 tf.loadLayersModel()。这在 loader.js 文件中调用:
const model = await tf.loadLayersModel(url);
model.summary();
模型打印如下所示:
# 图 5.2 用于识别 MNIST 图像和迁移学习 convnet 的结果

如图 5.2 所示,该模型由 12 层组成[74]。它的所有 600k 左右的参数都是可训练的,就像我们目前看到的所有 TensorFlow.js 模型一样。请注意, loadLayersModel()不仅加载模型的拓扑,还加载模型的所有权重值。因此,加载的模型可以预测从 0 到 4 的数字类别。然而,我们不是使用模型。相反,我们将训练模型来识别新的数字(即 5 到 9)。
查看“retain”按钮的回调函数(在 index.js 的 retrainModel()函数中),您可以注意到几行代码,如果选择了“freeze feature layers” (默认选中),这些代码将模型前 7 层的 trainable 属性设置为 false。
# 清单 5.1 在开始迁移学习之前“冻结”convnet 的前几层的代码。
const trainingMode = ui.getTrainingMode();
if (trainingMode === 'freeze-feature-layers') {
console.log('Freezing feature layers of the model.');
for (let i = 0; i < 7; ++i) {
this.model.layers[i].trainable = false;
}
} else if (trainingMode === 'reinitialize-weights') {
const returnString = false;
this.model = await tf.models.modelFromJSON({
modelTopology: this.model.toJSON(null, returnString)
});
}
this.model.compile({
loss: 'categoricalCrossentropy',
optimizer: tf.train.adam(0.01),
metrics: ['acc']
});
this.model.summary();
那有什么用?默认情况下,通过 loadLayerModel()方法加载模型或从头创建模型后,模型的每个层的可训练属性都为 true。可训练属性在训练期间使用(即调用 fit()或 fitDataset()方法)。它告诉优化器是否应该更新层的权重。默认情况下,模型所有层的权重都会在训练期间更新。但是,如果将模型的某些层的属性设置为 false,则在训练期间不会更新这些层的权重。在 TensorFlow.js 术语中,这些层变得不可训练或冻结。清单 5.1 中的代码冻结了模型的前七层,从 conv2d 输入层到 flatten 层,而最后几层(稠密层)是可训练的。
但是,仅仅设置层的 trainable 属性是不够的:如果您只是修改 trainable 属性并立即调用模型的 fit()方法,您将看到在 fit()调用期间这些层的权重仍然会更新。您需要在调用 Model.fit()之前调用 Model.compile(),以便可训练的属性更改生效,如清单 5.1 所示。我们前面提到 compile()调用配置优化器、损失函数和度量。但是,该方法还允许模型刷新要在调用期间更新的权重变量列表。在 compile()调用之后,我们再次调用 summary()来打印模型的新结果。通过将新摘要与上面的旧摘要进行比较,您可以看到,模型的某些重量变得不可训练:
Total params: 600165
Trainable params: 590597
Non-trainable params: 9568
您可以验证非可训练参数数量 9568 是两个具有权重的冻结层(即两个 conv2d 层)中权重参数的总和。请注意,我们冻结的某些层不包含权重(例如,maxPooling2d 层和 flatten 层),因此在冻结时不参与不可训练参数的计数。
迁移学习的实际代码如清单 5.2 所示。在这里,我们使用与从头开始训练模型相同的方法。在这个调用中,我们使用 validationData 来测量模型在训练期间没有看到的数据上的准确度。此外,我们在 fit()中使用两个回调,一个用于更新 UI 中的进度条,另一个用 tfjs-vis 模块绘制损失和精度曲线(更多细节将在第 7 章中介绍)。这展示了我们之前没有提到过 fit()API 的一个方面:您可以为 fit() 提供一个回调或一个由多个回调组成的数组。在后一种情况下,训练期间将调用所有回调(按在数组中指定的顺序)。
# 清单 5.2 迁移学习是基于 Model.fit()方法的,我们用它从头开始训练模型。
await this.model.fit(this.gte5TrainData.x, this.gte5TrainData.y, {
batchSize: batchSize,
epochs: epochs,
validationData: [this.gte5TestData.x, this.gte5TestData.y],
callbacks: [ #A:
ui.getProgressBarCallbackConfig(epochs),
#B:
tfVis.show.fitCallbacks(surfaceInfo, ['val_loss', 'val_acc'], {
zoomToFit: true,
zoomToFitAccuracy: true,
height: 200,
callbacks: ['onEpochEnd'],
}),
]
});
迁移学习如何进行?如图 5.3A 所示,经过 10 个阶段的训练后,它的精确度达到了 96.8%左右,在一台相对新的笔记本电脑上大约需要 15 秒——不错。但这与从头开始训练模型相比又如何呢?我们可以做一个实验,在这个实验中,我们在 fit()调用之前随机地重新初始化预训练模型的权重。如果在单击“重新训练”按钮之前选择“训练模式”下拉菜单的“重新初始化权重”选项,则会发生这种情况。结果显示在下图 B 中。通过比较图 B 和图 A 可以看出,模型权重的随机重新初始化会导致损失会从一个明显较高的值(0.36 比 0.30)开始,而准确度从一个显著较低的值(0.88 比 0.91)开始。重新初始化的模型最终的验证精度也比重用基础模型的权重的模型低(约 0.968)。这些差异反映了迁移学习的优势:通过重用模型的早期层(即特征提取层)中的权重,相对于从头学习,模型获得了良好的开端。这是因为在迁移学习任务中遇到的数据与用于训练原始模型的数据相似。数字 5-9 的图像与数字 0-4 的图像有很多共同点:它们都是具有黑色背景的灰度图像;它们具有相似的视觉模式(具有相似宽度和曲率的笔划)。因此,该模型学习如何从数字 0-4 中提取的特征对于学习如何对新数字(5-9)进行分类也很有用。
# 图 5.3 MNIST convnet 上迁移学习的损失与验证曲线。A: 前七层模型冻结后得到的曲线。B: 随机重新初始化权重得到的曲线。C: 在不冻结任何预训练模型层情况下得到的曲线。注意,三个图的 y 轴不同。D: 多系列图,显示同一轴上图 A-C 的损耗和精度曲线,以便于比较。
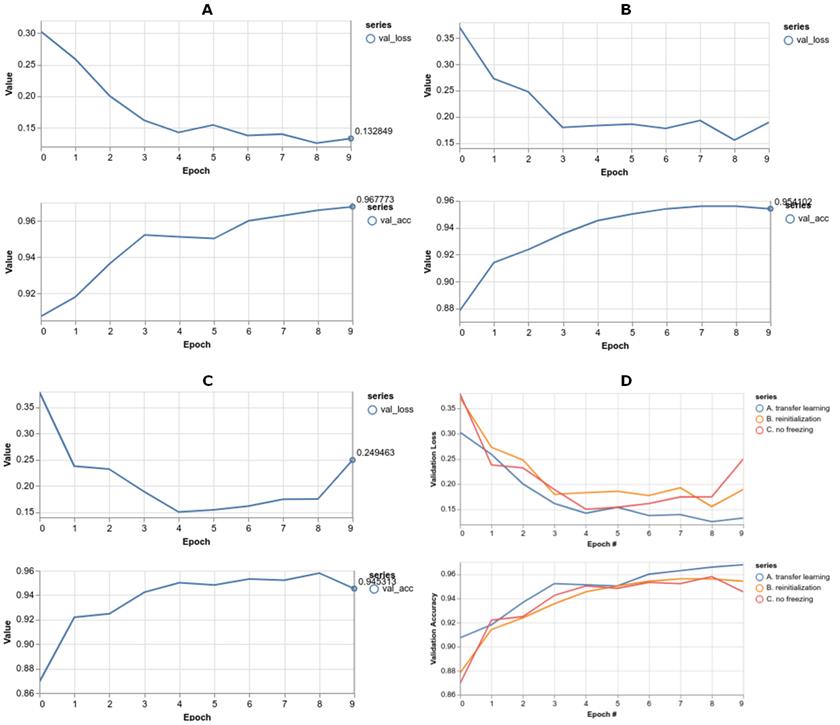
如果我们不冻结要素层的权重呢?“Training mode”下拉菜单中的“Don’t freeze feature layers”选项允许您执行此实验。结果如图 5.3 C 所示。与 a 组的结果有一些值得注意的差异:
- 在没有特征层冻结的情况下,损失值升高(例如,在第一个周期之后:0.37 vs.0.27);精度降低(0.87 vs.0.91)。为什么呢?当预训练模型开始在新的数据集上训练时,由于预训练的权值对五个新的数字产生本质上随机的预测,因此预测将包含大量的误差。因此,损失函数将具有非常高的值和陡坡。这导致在训练的早期阶段计算的梯度非常大,进而导致模型的所有权重出现较大波动。因此,所有层的权重都将经历一段大的波动期,这将导致图 C 中所示的更高的初始损失。在正常迁移学习方法(图 a)中,模型的前几层被冻结,因此被“屏蔽”以避免这些大的初始权重扰动。
- 由于较大初始扰动,通过无冻结方法获得的最终精度(~0.945,图 C)与使用层冻结的正常迁移方法(~0.968,图 A)相比没有明显的提高。
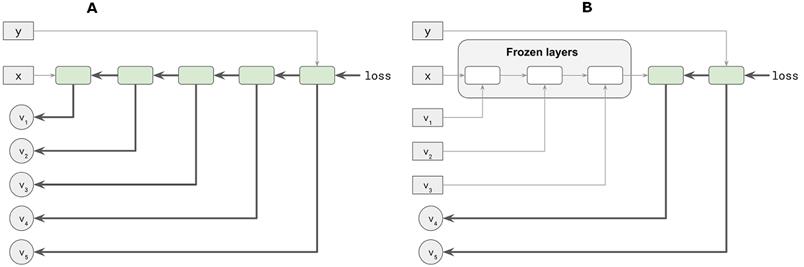
- 当没有模型的层被冻结时,训练需要更长的时间。例如,在我们使用的一台笔记本电脑上,使用冻结的功能层训练模型大约需要 30 秒,而不使用任何冻结层训练模型大约需要两倍的时间(60 秒)。下面的图 5.4 以图解的方式说明了这背后的原因。在反向传播过程中,冻结层会从中取出,这会导致每一批 fit()调用执行得更快。
这些点展现了迁移学习的层冻结方法优势:它利用从基本模型中提取的特征层,并在新训练的早期阶段保护它们不受大的权重扰动,从而在较短的训练时间内获得更高的精度。
# 图 5.4 反向传播的示意图,解释了为什么冻结模型的某些层会加快训练速度。在此图中,反向传播路径由指向左侧的黑色粗箭头显示。A 组:当没有图层被冻结时,模型的所有权重(v1-v5)都需要在每个训练步骤中更新,因此都涉及反向传播,由厚黑色箭头表示。注意,特性(x)和目标(y)从不包含在反向传播中,因为它们的值不需要更新。B 组:通过冻结模型的前几层,权重的子集(v1-v3)不再是反向传播的一部分。取而代之的是,它们变得类似于 x 和 y,而 x 和 y 只是被当作常数来考虑损耗的计算。结果,反向传播所需的计算量减少,训练速度提高。
在我们进入下一节之前的最后两个讨论。首先,模型自适应,即对模型进行再训练,使其更好地处理来自特定用户的输入数据的过程,使用冻结基本层的技术,同时通过对特定用户数据的训练来改变前几层的权重。尽管我们在本节中解决的问题并不涉及来自不同用户的数据,而是具有不同标签的数据。其次,您可能想知道如何在调用前后验证冻结层(即本例中的 conv2d 层)的权重是否确实相同。做这个验证并不难。我们把它作为练习留给你(见本章末尾的练习 2)。
# 5.1.2 不兼容输出形状的迁移学习:使用基本模型的输出创建新模型
在上一节中的迁移学习示例中,基本模型的输出形状与新的输出形状相同。此属性在许多其他迁移学习情况下不适用(请参见图 5.5)。例如,如果要使用最初在五位数上训练的基本模型来对四个新位数进行分类,则上述方法将不起作用。一个更常见的场景如下:给定一个在 ImageNet 分类数据集(由 1000 个输出类组成)上经过训练的深度神经网络,您手头有一个图像分类任务,它涉及的输出类数量要少得多(图 5.5 中的案例 B)。也许这是一个二值分类问题:图像是否包含人脸,或者这是一个只有少数类的多类分类问题:图片包含什么样的商品项(请回想本章开头的例子)。在这种情况下,基本模型的输出形状不适用于新问题。
# 图 5.5 根据新模型的输出形状和激活程度与原模型相同或不同,将迁移学习分为三种类型。A: 新模型的输出形状和激活函数与初始模型相匹配。第 5.1.1 节将 MNIST 模型转移到新的数字上就是这种迁移学习的一个例子。B: 新模型与基本模型具有相同的激活类型,因为原始任务和新任务属于同一类型(例如,两者都是多类分类)。然而,输出形状是不同的(例如,新任务涉及不同数量的类)。这种类型的迁移学习的例子可以在第 5.1.2 节(通过网络摄像头以 Pac ManTM[75]的方式控制视频游戏)和第 5.1.3 节(识别一组新的口语)中找到。C: 新任务与原来的任务类型不同(例如,回归与分类)。基于 MobileNet 的目标检测模型就是一个例子。
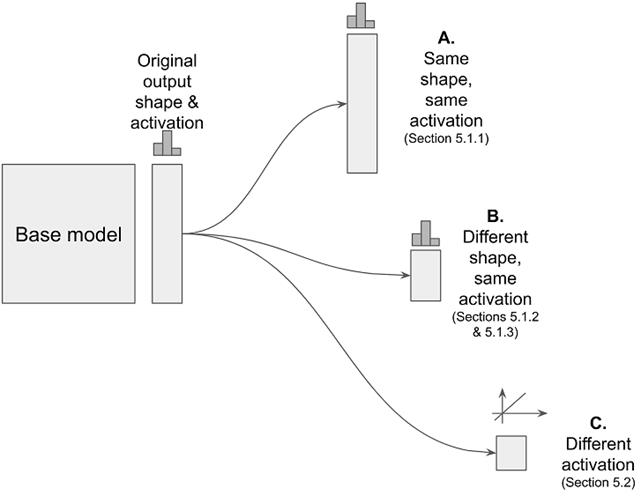
在某些情况下,甚至机器学习任务的类型也不同于基本模型所训练的任务类型。例如,您可以通过在分类任务的基础模型上应用迁移学习来执行回归任务(即,预测一个数字,图5.5中的案例C)。在第5.2节中,您将看到迁移学习的一个更有趣的用途,即使用迁移学习来预测一组数字,而不是单个数字,以便检测和定位图像中的对象。
这些情况都涉及到与基础模型不同的输出形状。这就需要建立一个新的模型。但是,由于我们正在进行迁移学习,新的模式将不会从头开始创建。相反,它将使用基本模型。我们将在 tfjs-examples 库中 webcam-transfer-learning 的示例中说明如何做到这一点。
要查看此示例的运行情况,请确保您的机器具有前置摄像头,因为此示例将从摄像头收集数据进行迁移学习。如今,大多数笔记本电脑和平板电脑都配有内置前置摄像头。但是,如果您使用的是台式计算机,则可能需要找到一个网络摄像头并将其连接到计算机上。与前面的示例类似,您可以使用以下命令签出并运行演示:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/webcam-transfer-learning
这个有趣的演示通过在 MobileNet 的 TensorFlow.js 实现上应用迁移学习,将您的网络摄像头变成一个游戏控制器,并允许您使用它玩 Pac Man 游戏。让我们通过三个步骤来运行演示:数据收集、模型迁移学习和播放。
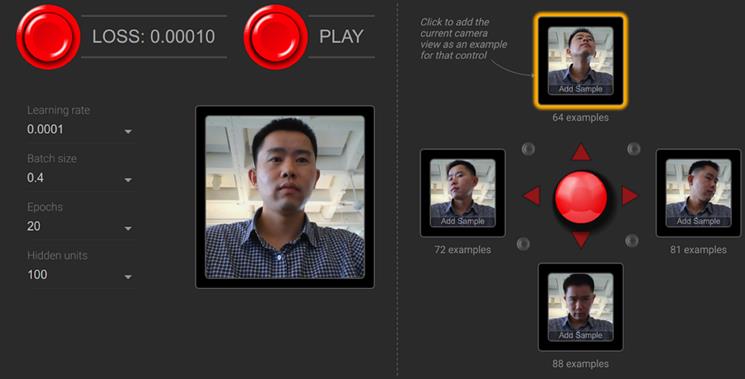
迁移学习的数据是从您的网络摄像头收集的。演示程序在浏览器中运行后,您将在页面右下角看到四个黑色正方形。它们的排列方式类似于任天堂(R)系列电脑控制器上的四个方向按钮。它们对应于模型将被训练以实时识别的四个类。这四类对应着吃豆人要去的四个方向。当您单击并按住其中一个按钮时,将通过网络摄像头以每秒 20-30 帧的速度收集图像。方块下方的数字告诉您迄今为止已为此控制器方向收集了多少图像。为了获得最佳的迁移学习质量,请确保 1)每类至少收集 50 幅图像,2)在数据收集期间稍微移动头部和面部,使训练图像包含更多的多样性,这有利于模型的健壮性,您将获得迁移学习。在这个演示中,大多数人将头转向四个方向(向上、向下、向左和向右,见图 5.6),以指示 Pac-Man 应该走哪条路。但是你可以使用任何你想要的头部位置,面部表情,甚至手势作为输入图像,只要在视觉上类与类之间有差别就可以。
采集完训练图像后,点击“训练模型”按钮,即可开始迁移学习过程。迁移学习只需要几秒钟。随着迁移学习的进行,您应该会看到屏幕上显示的损失值越来越小,直到达到非常小的正值(例如 0.00010)并停止改变。此时,迁移学习模型已经得到训练,您可以使用它来玩游戏。要开始游戏,只需按“播放”按钮,等待游戏状态结束。然后,模型将开始对来自网络摄像头的图像流进行实时推断。在每个视频帧中,获胜的类(即迁移学习模型分配的概率得分最高)将在 UI 的右下角以亮黄色突出显示。此外,它还将控制 Pac-Man 向相应的方向移动(除非被墙挡住)。
# 图 5.6 网络摄像头迁移学习示例的用户界面[76]。
对于那些不熟悉机器学习的人来说,这个演示可能看起来很神奇,但它仅仅基于一个使用 MobileNet 执行四类分类任务的迁移学习算法。该算法利用网络摄像头采集的少量图像数据。通过在收集图像时执行的“单击并按住”操作,可以方便地标记这些图像。由于迁移学习的强大功能,这个过程不需要太多数据或训练时间(甚至在智能手机中也能工作)。这就是这个演示的工作原理。如果您想了解技术细节,请在下一节中与我们一起深入了解下面的 TensorFlow.js 代码。
# 5.1.2.1 深入研究网络摄像头迁移学习
清单 5.3 中的代码负责加载基本模型。特别是,我们加载的 MobileNet 版本可以在 TensorFlow.js 中高效运行。信息框 5.1 描述 python 的深度学习库 Keras 中的模型是如何转换的。模型加载后,我们使用 getLayer()方法获取其一个层。getLayer()允许您按名称指定层(在本例中'conv_pw_13_relu')。您可能还记得从第 2.4.2 节访问模型层的另一种方法,即通过索引到模型的 layers 属性,该属性将模型的所有层都保存为 JavaScript 数组。只有当模型由少量层组成时,这种方法才易于使用。我们在这里处理的 MobileNet 模型有 93 层,这种方法则显得脆弱(例如,如果将来在模型中添加更多层呢?)因此,如果我们假设 MobileNet 的作者在发布新版本的模型时会保持关键层的名称不变,基于名称的 getLayer()方法更可靠。
# 清单 5.3 加载 MobileNet 并从中创建“截断的”模型(来自 webcam transfer learning/index.js)
async function loadTruncatedMobileNet() {
const mobilenet = await tf.loadLayersModel(
'https://storage.googleapis.com/tfjs-models/tfjs/mobilenet_v1_0.25_224/model.json'
);
const layer = mobilenet.getLayer('conv_pw_13_relu');
return tf.model({
inputs: mobilenet.inputs,
outputs: layer.output
});
}
# 信息框 5.1:将模型从 Python Keras 转换为 TensorFlow.js 格式
TensorFlow.js 与 Keras 具有高度的兼容性和互操作性,Keras 是最流行的 Python 深度学习库之一。兼容性带来的好处之一是,您可以利用 Keras 中的许多所谓“应用程序”。这些应用程序是一组预先训练好的深度神经网络(请参见https://keras.io/applications/)。Keras的作者在ImageNet等大型数据集上对这些神经网络进行了艰苦的训练,并通过库提供了这些,以便我们可以重用包括推理和迁移学习在内的案例。对于那些在Python中使用Keras的人来说,导入应用程序只需要一行代码。由于上面提到的互操作性,TensorFlow.js用户也很容易使用这些应用程序。以下是它所采取的步骤:
- 确保已安装名为 tensorflowjs 的 Python 包。最简单的安装方法是通过 pip 命令:
pip install tensorflowjs
- 通过 Python 源文件或在交互式 Python REPL 中运行以下代码,例如:
import keras
import tensorflowjs as tfjs
model = keras.applications.mobilenet.MobileNet (alpha=0.25)
tfjs.converters.save_keras_model(model,'/tmp/mobilnet_0.25')
前两行导入必需的 keras 和 tensorflowjs 模块。第三行将 MobileNet 加载到 Python 对象(model)中。实际上,您可以用与打印 TensorFlow.js 模型的摘要几乎相同的方式打印模型的摘要,即 model.summary().。您可以看到,模型的最后一层(即模型的输出)确实有一个形状(None, 1000)(相当于 JavaScript 中的形状[null, 1000]),反映了 MobileNet 模型所训练的 1000 类 Imagenet 分类任务。我们为此构造函数调用指定的关键字参数 alpha=0.25,来选择的 Mobilenet 版本较小。您也可以选择较大的值 alpha (e.g, 0.75, 1),相同的转换代码将继续工作。
上面代码片段的最后一行使用 tensorflowjs 模块中的方法将模型保存到磁盘上的指定目录。该行运行完成后,将在/tmp/mobilenet_0.25 处有一个新目录,其内容如下:
group1-shard1of6
group1-shard2of6
…
group1-shard6of6
model.json
这与我们在第 4.3.3 节中看到的格式完全相同,我们演示了如何使用 Node.js 版本的 TensorFlow.js 中的 save()方法将经过训练的 TensorFlow.js 模型保存到磁盘。因此,对于从磁盘加载基于 TensorFlow.js 程序,保存的格式与在 TensorFlow.js 中创建和训练的模型相同:它可以简单地调用 tf.loadLayersModel()方法并指向 model.json 文件的路径(在浏览器或 Node.js 中),这正是代码清单 5.3 中所示的。
加载的 MobileNet 模型已准备好执行模型最初训练的机器学习任务,即,将输入图像分类到 ImageNet 数据集的 1000 个类中。请注意,这个特定的数据集非常强调动物,特别是各种猫和狗(这可能与互联网上大量的此类图片有关!)对于那些对这种特殊用法感兴趣的人,tfjs 示例存储库中的 mobilenet 示例[77]演示了如何做到这一点。然而,我们在本章中并没有重点讨论 MobileNet 的这种直接使用;相反,我们探讨了如何使用加载的 MobileNet 来执行迁移学习。
tfjs.converters.save_keras_model() 方法不仅可以转换和保存 MobileNet,还可以转换和保存 DenseNet 和 NasNet 等其他 Keras 应用程序。在本章末尾的练习 3 中,您将练习将另一个 Keras 应用程序(MobileNetV2)转换为 TensorFlow.js 格式并将其加载到浏览器中。此外,应该指出的是, tfjs.converters.save_keras_model() 通常适用于您在 Keras 中创建和/或训练过的任何模型对象,而不仅仅是来自模型的对象。
一旦我们掌握了 conv_pw_13_relu 层我们该怎么办?我们创建了一个新的模型,它包含了原始 MobiletNet 模型从第一个(输入)层到该 conv_pw_13_relu 层的各个层。这是您第一次在本书中看到这种模型构造,因此需要一些仔细的解释。为此,我们首先需要引入符号张量的概念。
# 从符号张量创建模型
到目前为止你已经看到了张量。Tensor 是 TensorFlow.js 中的基本数据类型(dtype)。Tensor 对象携带给定形状和数据类型的具体数值,由 WebGL 纹理上的存储(如果在启用 WebGL 的浏览器中)或 CPU/GPU 内存(如果在 Node.js 中)支持。然而,符号张量是 TensorFlow.js 中的另一个重要类。符号张量不保存具体值,而只指定形状和数据类型。符号张量可以被认为是一个“槽”或“占位符”,在给定张量值具有兼容的形状和数据类型的情况下,实际的张量值可以插入到其中。在 TensorFlow.js 中,层或模型对象接受一个或多个输入(到目前为止,您只看到一个输入的情况),这些输入被表示为一个或多个符号张量。
让我们用一个可以帮助你理解符号张量的类比。考虑使用 Java 或 TypeScript(或您熟悉的任何其他静态类型语言)等编程语言编写的函数。函数接受一个或多个输入参数。函数的每个参数都有一个类型,该类型规定了可以作为参数传入的变量类型。然而,这个论点本身并没有任何具体的价值。这个参数本身只是一个占位符。符号张量类似于函数参数:它指定在该处可以使用哪种类型(即形状[78]和类型的组合)的张量。通过并行,静态类型语言中的函数具有返回类型。这相当于模型或层对象的输出符号张量。它是模型或层对象将输出的实际张量值的形状和数据类型的“蓝图”。
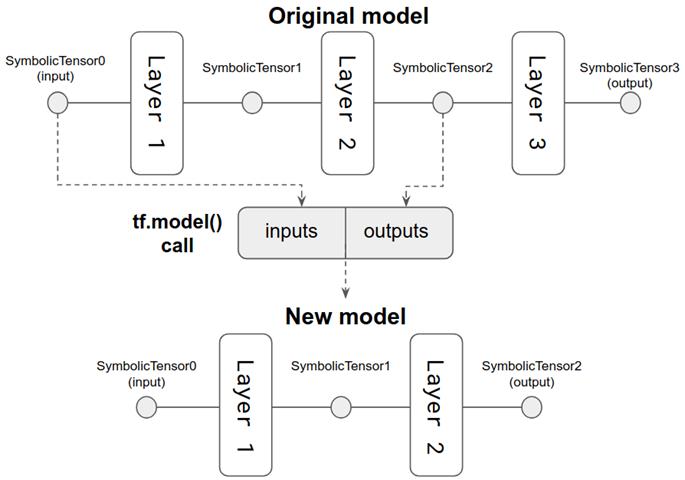
在 TensorFlow.js 中,模型对象的两个重要属性是其输入和输出。每一个都是一系列的符号张量。对于只有一个输入和一个输出的模型,两个数组的长度都是 1。类似地,层对象有两个属性:输入和输出,每个属性都是一个符号张量。符号张量可用于创建新模型。这是一种在 TensorFlow.js 中创建模型的新方法,它不同于您以前看到的方法,即使用方法 tf.sequential()和随后的 add()调用创建顺序模型。在新方法中,我们使用函数 tf.model() ,它接受一个带有两个强制字段的配置对象:inputs 和 outputs。inputs 必须是一个符号张量(或者是一组符号张量),同样地,outputs 也必须是。因此,我们可以从原始的 MobileNet 模型中获得符号张量,并将它们反馈给 tf.model()调用。结果是一个新的模型,它由原始 MobileNet 的部分组成。
这个过程如图 5.7 所示。(请注意,为了一个简单的图表,该图减少了实际 MobileNet 模型的层数。)需要认识到的重要一点是,从原始模型中提取并传递给 tf.model()调用的符号张量不是孤立的对象。相反,它们携带关于它们属于哪些层以及这些层如何相互连接的信息。对于熟悉数据结构中图形的读者来说,原始模型是一个符号张量图,连接边是层。通过将新模型的输入和输出指定为原始模型中的符号张量,我们正在提取原始 MobileNet 图的子图。成为新模型的子图包含 MobileNet 的前几层(特别是前 87 层),而后六层则被省略。深度神经网络最后几层有时称为“head”,我们对 tf.model() 调用所做的操作可以称为“截断”模型。截断的 MobileNet 保留特征提取层,而丢弃头部。为什么头部有六层?这是因为这些层特定于 MobileNet 最初训练的 1000 类分类任务。这些层对于我们所面临的四类分类任务没有用处。
# 图 5.7 解释如何从 MobileNet 创建新(“截断”)模型的示意图。有关相应的代码,请参见清单 5.3 中的 tf.model()调用。每一层都有一个输入和一个输出,它们都是符号张量实例。在原始模型中,符号张量 0 是第一层的输入,是整个模型的输入。它被用作新模型的输入符号张量。另外,我们将中间层的输出符号张量(相当于 conv_pw_13_relu)作为新模型的输出张量。因此,我们得到一个由原始模型的前两层组成的模型,如图底部所示。原始模型的最后一层(即输出层,有时称为模型的头部)被丢弃。这就是为什么这样的方法有时被称为“截断”模型。请注意,为了清晰起见,此图描述了具有少量层的模型。清单 5.3 中的代码实际发生的情况涉及一个模型,与此图中所示的模型相比,该模型具有更多(93)层。
# 基于嵌入的迁移学习
截短的 MobileNet 的输出是原始 MobileNet 的中间层的激活[79]。但是 MobileNet 中间层激活对我们有什么帮助呢?答案可以在函数中看到,该函数处理单击并按住四个黑色方块中的每一个方块(清单 5.4)的事件。每当网络摄像头提供输入图像时(通过该 capture() 方法),我们调用截断 Mobilenet 的 predict() 方法,并将输出保存在一个名为 controllerDataset 的对象中,稍后将用于迁移学习。
但是如何解释被截断的 MobileNet 的输出呢?对于每个图像输入,它都是一个形状张量[1,7,7,256]。它不是任何分类问题的概率,也不是任何回归问题的预测值。它是输入图像在一定高维空间中的一种表示。这个空间有 77256,大约 12.5k 的尺寸。虽然空间有很多维度,但与原始图像相比,它的维度较低,因为原始图像有 224224 个图像维度和 3 个颜色通道,具有 224224*3≈150k 维度。因此,截短的 MobileNet 的输出可以看作是图像的有效表示。这种输入的低维表示常被称为嵌入。我们的迁移学习将基于从网络摄像头收集的四组图像的嵌入。
# 清单 5.4 使用截断的 MobileNet 从网络摄像头(从 index.js)获取输入图像的嵌入
ui.setExampleHandler(label => {
tf.tidy(() => {
const img = webcam.capture();
controllerDataset.addExample(truncatedMobileNet.predict(img), label);
ui.drawThumb(img, label);
});
});
现在我们有了一种方法来获取网络摄像头图像的嵌入,我们如何使用它们来预测给定图像对应的方向?为此,我们需要一个新的模型,它以嵌入为输入,输出四个方向类的概率值。清单 5.5 中的代码创建了这样一个模型。
# 清单 5.5 嵌入截断的 Mobilenet(来自 index.js)中的图像创建预测控制器方向的模型
model = tf.sequential({
layers: [
tf.layers.flatten({
inputShape: truncatedMobileNet.outputs[0].shape.slice(1)
}), #A:
tf.layers.dense({
units: ui.getDenseUnits(),
activation: 'relu',
kernelInitializer: 'varianceScaling',
useBias: true
}), #B:
tf.layers.dense({
units: NUM_CLASSES,
kernelInitializer: 'varianceScaling',
useBias: false,
activation: 'softmax'
}) #C:
]
});
与截断的 MobileNet 相比,清单 5.5 中创建的新模型的大小要小得多。它只有三层:
- 输入层是一个扁平层。它将三维嵌入从截断模型转换为一维张量,随后的稠密层可以采用这种张量。我们在第四章中看到了 MNIST convnets 中扁平层的类似用法。我们让它的输入形状与截断 MobileNet 的输出形状匹配(不带批处理维度),因为新模型将由截断的 MobileNet 提供嵌入。
- 第二层是隐藏层。它是隐藏的,因为它既不是模型的输入层也不是输出层。相反,它被夹在另外两层之间,以增强模型的容量。这与您在第 2 章中遇到的多层感知器(MLPs)非常相似。这个隐藏的致密层有一个 relu 激活。回想一下,在第 3.1.1.2 节中,我们讨论了对这样的隐藏层使用非线性激活的重要性。
- 第三层是新模型的最终(输出)层。它有一个 softmax 激活,它适应了我们面临的多类分类问题(即,四个类: Pac-Man 每个方向)。
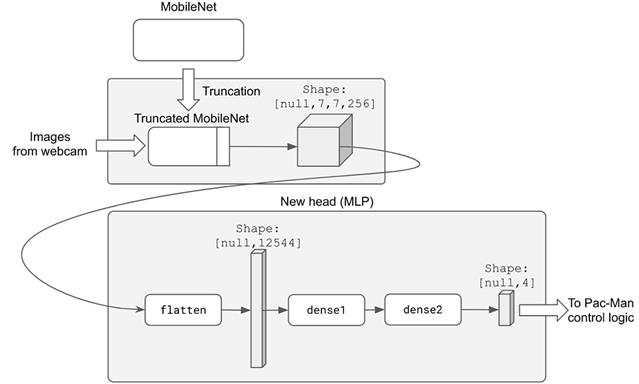
因此,我们基本上在 MobileNet 的特征提取层之上构建了一个 MLP。MLP 可以被认为是 MobileNet 的一个新头部,即使在这种情况下,特征提取器(即截断的 MobileNet)和头部是两个独立的模型(参见下面的图 5.8)。由于两个模型的缘故,不可能直接使用(形状为[numExamples, 224, 224, 3])图像张量来训练新的头部。相反,新的头部必须接受图像嵌入的训练,即截短的 MobileNet 的输出。幸运的是,我们已经收集了那些嵌入的张量(清单 5.4)。训练新的头只需要调用嵌入张量的 fit()方法。在 index.js 中的 train()函数中实现这一点的代码非常简单,我们将不再详细讨论。
# 图 5.8 迁移学习算法的示意图,作为网络摄像头迁移学习示例的基础。
一旦迁移学习完成,截短的模型和新的头部将一起使用,从网络摄像头的输入图像中获得概率分数。您可以在 index.js 的 predict()函数中找到代码,如清单 5.6 所示。特别是涉及两个 predict()方法。第一个调用使用截断的 Mobilenet 将图像张量转换为其嵌入;第二个调用使用经过迁移学习训练的新头将嵌入转换为四个方向的概率分数。清单 5.6 中的后续代码获取获胜索引(即对应于四个方向中最大概率得分的索引),并使用它来指导 Pac Man 和更新 UI 状态。和前面的例子一样,我们不讨论例子中的 UI 部分,因为它们不是机器学习算法的核心。你可以根据自己的喜好学习和使用 UI 代码。
# 清单 5.6 从迁移学习后的摄像头输入图像获取预测(来自 index.js)
async function predict() {
ui.isPredicting();
while (isPredicting) {
const predictedClass = tf.tidy(() => {
const img = webcam.capture(); #A:
const embedding = truncatedMobileNet.predict(img); // B:
const predictions = model.predict(activation); #C:
return predictions.as1D().argMax(); #D:
});
const classId = (await predictedClass.data())[0]; #E:
predictedClass.dispose();
ui.predictClass(classId); #F:
await tf.nextFrame();
}
ui.donePredicting();
}
这结束了我们对网络摄像头迁移学习示例中与迁移学习算法相关的部分的讨论。我们在本例中使用的方法的一个有趣的方面是,训练和推理过程涉及两个独立的模型对象。这有助于我们说明如何从预训练模型的中间层获得嵌入。这种方法的另一个优点是它公开了嵌入,使直接使用这些嵌入的机器学习技术更容易应用。这种技术的一个例子是 k 近邻(kNN,在信息框 5.2 中讨论)。但是,直接暴露嵌入也可能被视为一个缺点,因为
- 这会导致代码稍微复杂一些。例如,推理需要两个 predict()调用才能对单个图像执行推理。
- 假设我们想保存模型,以便在以后的会话中使用或转换为 non-TensorFlow.js 库,那么截断的模型和新的 head 模型需要独立保存。
- 在某些特殊情况下,迁移学习将涉及在基础模型的某些部分(例如,截断 MobileNet 的前几层)上的反向传播。当底部和头部是两个独立的对象时,这是不可能的。
在下一节中,我们将展示一种克服这些限制的方法,即为迁移学习形成一个单一的模型对象。它将是一个端到端的模型,可以将原始格式的输入数据转换为最终所需的输出。
# 信息框 5.2: 基于嵌入的 k 近邻分类
在机器学习中,有很多非神经网络方法来解决分类问题。其中最著名的是 k 近邻(kNN)算法。与神经网络不同,kNN 算法不需要训练步骤,更容易理解。 我们可以用几句话来描述 kNN 分类的工作原理:
- 选择正整数 k(例如 3)。
- 您收集了许多引用示例,每个示例都用 true 类标记。通常,所收集的参考示例的数量至少是 k 的几倍。每个示例都表示为一系列实数,即向量。这一步类似于神经网络方法中训练实例的收集。
- 为了预测新输入的类别,计算新输入的矢量表示与所有参考示例的矢量表示之间的距离。然后你对距离进行排序。通过这样做,您可以在向量空间中找到最接近输入的 k 个引用示例。它们被称为输入的“k 近邻”(算法的同名)。
- 查看 k 个最近邻的类,并使用其中最常见的类作为输入的预测。换句话说,你让 k 个最近的邻居对预测的类进行“投票”。
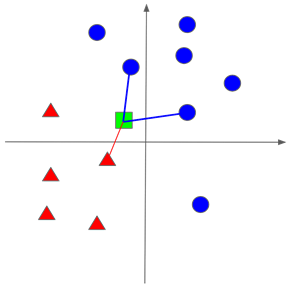
下面的图 5.9 显示了该算法的一个示例。
# 图 5.9 二维嵌入空间中 kNN 分类的一个例子。在这种情况下,k=3 有两个类(三角形和圆形)。三角形类有五个参考示例,圆形类有七个参考示例。输入示例表示为正方形。与输入最近的三个邻居由连接它们与输入的线段表示。因为三个最近邻中有两个是圆,所以输入示例的预测类将是圆。
从上面的描述可以看出,kNN 算法的一个关键要求是每个输入示例都表示为一个向量。像我们从截短的 MobilNet 中得到的嵌入是这种向量表示的好候选,原因有二。首先,它们通常比原始输入具有更低的维数,因此减少了距离计算所需的存储和计算量。其次,嵌入通常在输入中捕获更重要的特征(例如,图像中的重要几何特征,见图 4.5),而忽略不重要的特征(例如,亮度和大小),因为它们是在大型分类数据集上训练的。在某些情况下,嵌入为我们提供了向量表示法,这些表示法最初甚至没有表示为数字(例如,第 9 章中的单词嵌入)。
与神经网络方法相比,kNN 不需要任何训练。在参考实例数量不太多,输入维数不太高的情况下,使用 kNN 比训练神经网络并运行它进行推理更有效。
然而,kNN 推理不能很好地适应数据量。特别是,给定 N 个参考示例,kNN 分类器必须计算 N 个距离,以便对每个输入进行预测[80]。当 N 变大时,计算量会变得很难处理。相比之下,神经网络的推理并不随训练数据的多少而改变。一旦网络被训练,有多少例子进入训练并不重要。网络上的前向传递所需的计算量只是网络拓扑结构的一个函数。
如果您有兴趣将 kNN 用于您的应用程序,请查看基于 TensorFlow.js 的 WebGL 加速 kNN 库:https://www.npmjs.com/package/@TensorFlow models/kNN classifier
# 5.1.3 通过微调充分利用迁移学习:音频示例
在前面的章节中,迁移学习的例子涉及视觉输入。在本例中,我们将展示迁移学习对表示为谱图图像的音频数据也起作用。回想一下,我们在第 4.4 节中介绍了用于识别语音命令(孤立的简短口语)的 convnet。我们构建的语音命令识别器只能识别 18 个不同的单词(例如,“one”、“two”、“up”、“down”)。如果你想训练其他单词的识别器呢?可能您的特定应用程序要求用户说出特定的单词,例如“red”或“blue”,甚至是由用户自己选择的单词,或者您的应用程序是为讲英语以外的其他语言的用户设计的。这是迁移学习的一个经典例子:在手头有少量数据的情况下,您可以尝试从头开始训练一个模型,但是使用一个预先训练的模型作为基础,您可以花费较少的时间和计算资源,同时获得更高的精度。
# 5.1.3.1 如何在语音命令示例应用程序中进行迁移学习
我们在本例中描述迁移学习的工作原理之前,熟悉如何通过 UI 使用迁移学习特性对您很有帮助。要使用用户界面,请确保您的计算机连接了音频输入设备(即麦克风),并且在系统设置中将音频输入音量设置为非零值。要下载演示程序的代码并运行演示程序,请执行(与第 4.4.1 节中的过程相同):
git clone https://github.com/tensorflow/tfjs-models.git
cd tfjs-models/speech-commands
yarn && yarn publish-local
cd demo
yarn && yarn link-local && yarn watch
当用户界面启动时,请对浏览器请求您访问麦克风的权限回答“是”。图 5.10 显示了演示的一个示例屏幕截图。启动时,演示页面将使用指向 HTTPS URL 的 tf.loadLayerModel()方法自动从 Internet 加载一个预先训练的语音命令模型。加载模型后,将启用“开始”和“输入迁移字”按钮。如果单击““Start”按钮,演示程序将进入推理模式,在该模式下,它将连续检测 18 个基本单词(如屏幕上显示的)。每次检测到一个单词时,相应的单词框将在屏幕上亮起。但是,如果您单击“Enter transfer words”按钮,屏幕上将会显示一些其他按钮。这些按钮是从右侧文本输入框中逗号分隔的单词创建的。默认单词是“noise”、“red”、“green”。这些都是迁移学习模式将被训练来识别的词汇。但是如果你想训练一个换言之的传输模型,你可以自由地修改输入框的内容,只要你保留“noise”项。“噪音”是一个特殊的项目,你应该收集背景噪音样本,即没有任何语音的样本。这使得传递模型能够从沉默的时刻(背景噪声)中分辨出一个单词所说的时刻。当您单击这些按钮时,演示程序将从麦克风录制一秒钟的音频片段,并在按钮旁边显示其频谱图。word 按钮中的数字记录到目前为止为特定单词收集的示例数。
# 图 5.10 语音命令示例的迁移学习功能的示例屏幕截图。在这张截图中,用户输入了一组用于迁移学习的自定义单词:“feel”、“seal”、“veal”和“zeal”,此外还输入了总是需要的“noise”项。此外,用户为每个单词和噪声类别收集了 20 个示例。
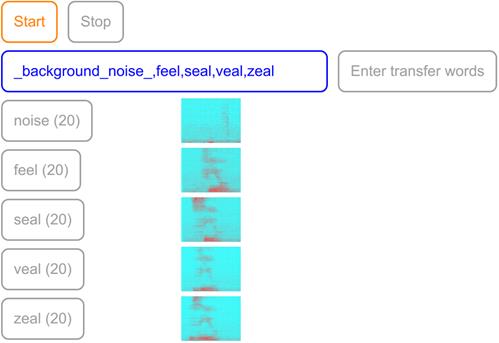
与机器学习问题的一般情况一样,您可以收集的数据越多(在可用的时间和资源允许的情况下),经过训练的模型就越好。示例应用程序要求每个单词至少有八个示例。如果您不想或无法自己收集声音样本,可以从https://storage.googleapis.com/tfjs-speech-model-test/2018-11-28T12.09.22.bin(文件大小:9MB)下载预收集的数据集,并使用用户界面“数据集IO”部分中的“Upload””按钮将其上载。
一旦数据集准备就绪,无论是通过文件上传还是您自己的样本收集,“Start transfer learning”按钮将启用。您可以单击按钮开始转移模型的训练。应用程序对你收集的音频频谱图执行 3:1 的分割,这样随机选择的 75%将用于训练,剩下的 25%将用于验证[81]。当迁移学习发生时,应用程序将显示训练集丢失和准确性值以及验证集值。训练完成后,您可以单击“Start”按钮,让演示开始连续识别迁移词,在此期间,您可以根据经验评估转移模型的准确性。
你应该用不同的单词集进行实验,看看它们如何影响你在对它们进行迁移学习后所能得到的准确度。在默认设置中,“red”和“green”这两个词在音素内容上是相当不同的。例如,它们的起始辅音是两个非常不同的音,“r”和“g”;它们的元音也听起来相当不同(“e”对“ee”);它们的结束辅音(“d”对“n”)。因此,只要为每个单词收集的示例数不太小(比如>=8),因为太小导致欠拟合或太大会导致过拟合(请参阅第 8 章),那么在传输训练结束时,您应该能够获得近乎完美的验证精度。
要使迁移学习任务对模型更具挑战性,请使用一组 1)更易混淆的单词和 2)更大的词汇。这就是我们对图 5.10 中的截图所做的。有一套四个词,听起来彼此相似的使用:“feel”, “seal”, “veal”, and “zeal”。这些单词有相同的元音和结束辅音,以及四个发音相似的开始辅音。从图右下角的精度曲线可以看出,模型要达到 90%以上的精度并非易事,为此,迁移学习的初始阶段必须辅以微调的附加阶段,即迁移学习技巧。
微调是一种技术,它可以帮助您达到更高的精度水平。如果您想了解微调的工作原理,请通过下面的“深入研究”部分进行操作。会有一些技术要点需要消化。但是,对迁移学习和相关 TensorFlow.js 实现的深入理解是值得的。
# 5.1.3.2 在迁移学习中深入研究微调
# 构建单一迁移学习模型
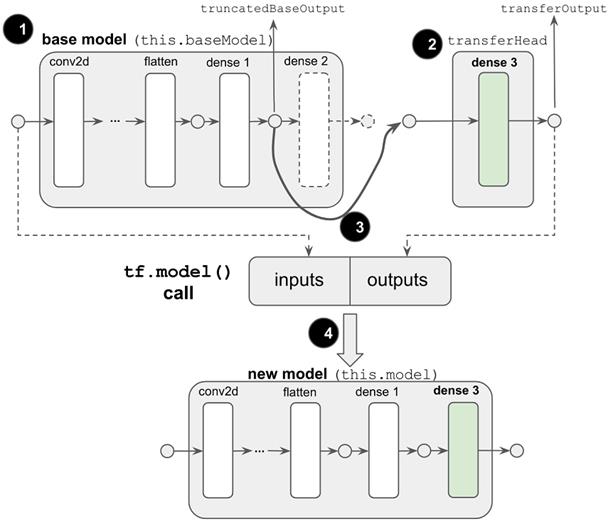
首先,我们需要了解语音迁移学习应用程序是如何创建迁移学习模型的。代码清单 5.7 是应用程序如何从基本语音命令模型(您在第 4.4.1 节中学习的模型)创建模型的。它首先找到模型的倒数第二层的密集层,然后得到它的输出 SymbolicTensor(即代码中的“truncatedBaseOutput”)。然后它创建了一个新的头部模型,只包含 dense 层。此新头的输入形状与“truncatedBaseOutput”的形状匹配,其输出形状与传输数据集中的字数匹配(例如,在上面图 5.7 的情况下为 5)。该 dense 层被配置为使用 softmax 激活,它适合于多类分类任务。
# 清单 5.7 将迁移学习模型创建为单个 tf.model 对象[82](来自 speech commands/src/browser_fft_recognizer.ts)。请注意,与本书中大多数其他代码列表不同,下面的代码是用 TypeScript 编写的。不熟悉 TypeScript 的读者可以忽略诸如“void”和“tf.SymbolicTensor”之类的类型符号。
private createTransferModelFromBaseModel(): void {
const layers = this.baseModel.layers;
let layerIndex = layers.length - 2;
while (layerIndex >= 0) {
if (layers[layerIndex].getClassName().toLowerCase() === 'dense') {
break;
}
layerIndex--;
} #A:
if (layerIndex < 0) {
throw new Error('Cannot find a hidden dense layer in the base model.');
}
this.secondLastBaseDenseLayer = layers[layerIndex]; #B:
const truncatedBaseOutput = layers[layerIndex].output as tf.SymbolicTensor;
#C:
this.transferHead = tf.layers.dense({
units: this.words.length,
activation: 'softmax',
inputShape: truncatedBaseOutput.shape.slice(1)
})); #D:
const transferOutput = #E:
this.transferHead.apply(truncatedBaseOutput) as tf.SymbolicTensor;
this.model = #F:
tf.model({inputs: this.baseModel.inputs, outputs: transferOutput});
}
新的 head 以一种新的方式使用:调用其 apply()方法,使用截断的 truncatedBaseOutput 符号张量作为输入参数。apply()是 TensorFlow.js 中每个层和模型对象上都可用的方法。apply()方法做什么?顾名思义,它在输入端“应用”新的头部模型,从而为您提供输出。
- 这里涉及的输入和输出都是符号,即它们是具体张量值的占位符。
- 如图 5.11 所示:符号输入(即 truncatedBaseOutput)不是一个独立的实体,而是基本模型的第二个最后密集层的输出。密集层从另一层接收输入,而另一层又从其上游层接收输入,以此类推。因此,truncatedBaseOutput 带有一个子图的基本模型:即子图之间的基本模型的输入和第二个最后密集层的输出。换句话说,它是基础模型的整个图形,减去第二个最后密集层之后的部分。因此,apply()调用的输出携带一个由该子图和新的密集层组成的图。在对 tf.model()函数的调用中,输出和原始输入一起使用,这将生成一个新模型。这个新模型与基础模型相同,只是它的头部被新的 dense 层所取代(参见图 5.11 的底部)。
# 图 5.11 为迁移学习创建新的端到端模型的方式的示意图。此图应与代码清单 5.7 一起阅读。图中与清单 5.7 中的变量相对应的部分用 Courier New 字体标记。(1) :得到原始模型从开始到倒数第二的稠密层的输出符号张量(用向下的粗箭头表示)。稍后将在步骤 3 中使用。(2) :将创建新的头部模型,该模型由单个输出密集层(标记为“dense 3”)组成。(3) :使用步骤 1 中的符号张量作为输入参数调用新头模型的 apply() 方法。该调用将输入连接到新的头模型和步骤 1 中截断的基础模型。(4) :调用 tf.model()函数时,apply()调用的返回值与原始模型的输入符号张量一起使用。此调用返回一个新模型,该模型包含原始模型从第一层到倒数第二层的所有层,以及新头部中的致密层。实际上,这将原始模型的旧头部与新头部互换,为后续传输数据的训练奠定了基础。请注意,为了视觉上的简单性,图中省略了实际语音命令模型的某些(七)层。在这个图中,着色层是可训练的,而白色层是不可训练的。
注意,这里的方法不同于我们在第 5.1.2 节中融合模型的方法。在那里,我们创建了一个截断的基模型和一个新的头部模型作为两个独立的模型实例。因此,对每个输入示例运行推理涉及两个 predict()调用。这里,新模型预期的输入与基本模型预期的音频谱图张量相同。同时,新模型直接输出生词的概率分数。每个推理只需要一个 predict()调用,因此是一个更简化的过程。通过将所有层封装在一个模型中,我们的新方法对我们的应用程序有一个额外的优势:它允许我们通过识别新词所涉及的任何层执行反向传播。这使我们能够执行微调技巧。这是我们将在下一节探讨的内容。
# 通过层解冻进行微调
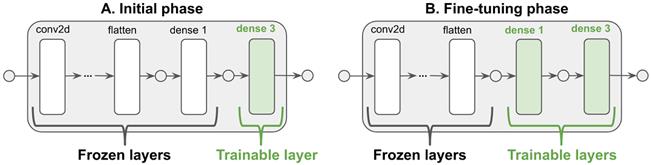
微调是模型训练初始阶段之后的迁移学习的可选步骤。在初始阶段,来自基础模型的所有层都被冻结(即,它们的 trainable 属性设置为 false),权重更新仅发生在头部层。我们已经在本章 mnist-transfer-cnn 和前面的示例 webcam-transfer-learning 中看到了这种类型的初始训练。在微调过程中,基本模型的某些层被解冻(即,它们的 trainable 属性设置为 true),然后再次根据传输数据对模型进行训练。该层解冻如图 5.12 所示。清单 5.8 的代码显示了在 TensorFlow.js 中为语音命令示例所做的工作。
# 图 5.12 如清单 5.8 中的代码所示,演示了在迁移学习的初始(A)和微调(B)阶段中冻结和解冻(即,可训练)层。注意,dense3 紧跟 dense1 其后的原因是 dense2(基本模型的原始输出)作为迁移学习的第一步被截断了(参见上面的图 5.11)
# 清单 5.8 初始迁移学习,然后进行微调(来自 speech commands/src/browser_fft_recognizer.ts)[83]。
async train(config?: TransferLearnConfig):
Promise<tf.History|[tf.History, tf.History]> {
if (config == null) {
config = {};
}
if (this.model == null) {
this.createTransferModelFromBaseModel();
}
this.secondLastBaseDenseLayer.trainable = false; #A:
this.model.compile({
loss: 'categoricalCrossentropy',
optimizer: config.optimizer || 'sgd',
metrics: ['acc']
}); #B:
const {xs, ys} = this.collectTransferDataAsTensors();
let trainXs: tf.Tensor;
let trainYs: tf.Tensor;
let valData: [tf.Tensor, tf.Tensor];
try {
if (config.validationSplit != null) {
const splits = balancedTrainValSplit(xs, ys, config.validationSplit); #C:
trainXs = splits.trainXs;
trainYs = splits.trainYs;
valData = [splits.valXs, splits.valYs];
} else {
trainXs = xs;
trainYs = ys;
}
const history = await this.model.fit(trainXs, trainYs, {
epochs: config.epochs == null ? 20 : config.epochs,
validationData: valData,
batchSize: config.batchSize,
callbacks: config.callback == null ? null : [config.callback]
}); #D:
if (config.fineTuningEpochs != null && config.fineTuningEpochs > 0) {
this.secondLastBaseDenseLayer.trainable = true; #E:
const fineTuningOptimizer: string|tf.Optimizer =
config.fineTuningOptimizer == null ? 'sgd' :
config.fineTuningOptimizer;
this.model.compile({
loss: 'categoricalCrossentropy',
optimizer: fineTuningOptimizer,
metrics: ['acc']
}); #F:
const fineTuningHistory = await this.model.fit(trainXs, trainYs, {
epochs: config.fineTuningEpochs,
validationData: valData,
batchSize: config.batchSize,
callbacks: config.fineTuningCallback == null ?
null :
[config.fineTuningCallback]
}); #G:
return [history, fineTuningHistory];
} else {
return history;
}
} finally {
tf.dispose([xs, ys, trainXs, trainYs, valData]);
}
}
关于清单 5.8 中的代码,有几点需要指出:
- 每次通过更改任何层的可训练属性冻结或解冻任何层时,都需要再次调用模型的 compile()方法才能使更改生效。我们已经在第 5.1.1 节中介绍了。
- 我们保留了一小部分训练数据以供验证。这确保了我们所看到的损失和精度反映了模型在反向传播过程中没有看到的输入上的情况。然而,我们将收集到的数据中的一小部分分割出来进行验证的方式与以前不同,值得注意。在 MNIST convnet 示例(第 4 章中的清单 4.2)中,我们使用'validationSplit'参数让 Model.fit()保留最后 15-20%的数据进行验证。同样的方法在这里不会很有效。为什么?这是因为与前面示例中的数据相比,我们这里的训练集要小得多。因此,盲目地拆分最后几个示例进行验证很可能会导致某些单词在验证子集中的表示不足。例如,假设您为“feel”、“seal”、“veal”和“zeal”四个单词中的每一个收集了 8 个示例,并从 32 个示例(即 8 个示例)中选择最后 25%进行验证,那么平均来说,验证子集中每个单词只有两个示例。由于随机性,有些单词可能在验证子集中只有一个示例,而其他单词可能根本没有示例!显然,如果验证集缺少特定的单词,那么它就不是一个很好的集来测量模型的准确性。这就是为什么我们使用自定义函数(清单 5.8 中的 balancedTrainValSplit)。此函数考虑了示例的真实单词标签,并确保所有不同的单词在训练和验证子集中都得到公平的表示。如果您有一个包含类似小数据集的迁移学习应用程序,那么最好也这样做。
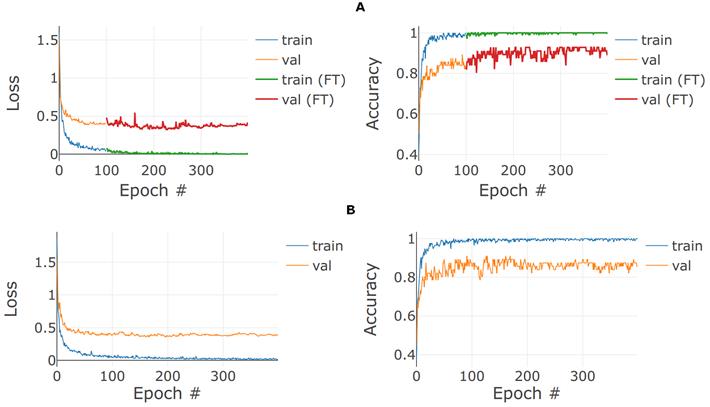
那么微调对我们有什么作用呢?在迁移学习的初始阶段,它提供了什么附加值?为了说明这一点,我们绘制了图 5.13A 中初始和微调阶段的损耗和精度曲线。这里涉及的传输数据集由四个单词组成,如图 5.10 所示。每条曲线的前 100 个阶段对应于初始阶段,而最后 300 个阶段对应于微调。可以看出,在初始训练的 100 个阶段接近尾声时,损失和精度曲线开始变平,并开始进入收益递减的阶段。验证子集的准确性降低了约 84%。(另一方面,注意只看训练子集的精度曲线它很容易接近 100%。)然而,解冻基础模型中的稠密层,重新编译模型,并开始训练的微调阶段,验证精度会变得不稳定,可以达到 90-92%,精度提高 6-8 个百分点。在验证损失曲线中也可以看到类似的效果。
为了说明无需微调对迁移学习进行微调的影响,我们在图 5.13 的面板 B 中展示了如果传输模型在相同数量(400)个阶段进行训练,而无需微调基本模型的前几层,会发生什么情况。当微调开始的前 10 个阶段时,面板 A 中发生的损失或精度曲线没有“拐点”。相反,损耗和精度曲线趋于平稳并收敛到更差的值。
# 图 5.13 A 组:迁移学习和随后微调的示例损失和精度曲线。 “FT”代表微调。请注意曲线的初始部分和微调部分之间的连接处的拐点。微调加速了损失降低提升了准确度,这是由于基础模型的前几层解冻,从而增加了模型的容量并适应了迁移学习数据中的独特特征。B 组:在没有微调的情况下,将传输模型训练为相等数量的阶段(即 400 个阶段)得到的损耗和精度曲线。请注意,与面板 a 相比,如果不进行微调,验证损失会收敛到一个更高的值,而验证精度会收敛到一个更低的值。请注意,虽然通过微调(面板 a)最终精度会达到约 0.9,但如果不进行微调(面板 B),则会停留在约 0.85。
那么为什么微调有帮助呢?可以理解为模型容量的增加。通过解冻基础模型的一些最顶层,我们允许传递模型在比初始阶段更高的维参数空间中最小化损失函数。这类似于在神经网络中添加隐藏层。对原始数据集(由“one”, “two”, “yes” “no”等词组成的数据集)的未冻结致密层的权重参数进行了优化,这可能对迁移词不是最优的。这是因为帮助模型区分这些原始单词可能不是使迁移词最容易彼此区分的表示。通过允许对迁移字的这些参数进行进一步优化(即微调),我们允许对迁移字的表示进行优化。因此,我们可以提高对迁移词的验证精度。注意,当迁移学习任务很难完成时(例如,这里有四个容易混淆的单词:“feel”、“seal”、“veal”和“zeal”),这种优化更容易看到。对于更简单的任务(例如,更清晰的单词,如“红色”和“绿色”),仅在初始迁移学习时,验证准确率就可以达到 100%。
您可能想问的一个问题是:这里我们只解冻了基础模型中的一个层,但是解冻更多的层会有帮助吗?简而言之,这取决于解冻更多的层会使模型具有更高的容量。但是,正如我们在第 4 章中提到的,并且将在第 8 章中更详细地讨论的那样,更高的容量会导致更高的过度拟合风险,特别是当我们面对一个小数据集时,比如在浏览器中收集的音频示例。在本章结束时,作为练习 4 的一部分,我们鼓励你自己进行实验。
让我们在 TensorFlow.js 中结束关于迁移学习的这一部分。我们介绍了在新任务中重用预先训练的模型的三种不同方法。为了帮助您在未来的迁移学习项目中抉择使用哪种方法,我们在下面的表 5.1 中总结了这三种方法及其相对的优缺点。
# 表 5.1 总结了 TensorFlow.js 中三种迁移学习方法及其优缺点。
| 方法 | 优点 | 缺点 |
|---|---|---|
| 使用原始模型并冻结其前几个(特征提取)层(第 5.1.1 节) | 简单方便 | 只有当迁移学习所需的输出形状和激活与原始模型的匹配时,才能工作 |
| 从原始模型获取内部激活层作为输入示例的嵌入,并创建以嵌入为输入的新模型(第 5.1.2 节) | 适用于需要不同于原始输出形状的迁移学习案例;嵌入张量是直接可访问的,使得 k-最近邻(kNN,参见信息框 5.2)分类器等方法成为可能 | 需要管理两个独立的模型实例;难以微调原始模型的层 |
| 创建包含原始模型特征提取层和新头部层的新模型(第 5.1.3 节) | 适用于需要不同于原始输出形状的迁移学习案例;只需管理一个模型实例;启用对特征提取层的微调 | 内部激活(嵌入)不可直接访问 |