与我交流

# 4.4 语音识别:在音频数据上应用卷积
到目前为止,我们已经展示了如何使用卷积网络执行计算机视觉任务。但是人类的感知不仅仅是视觉。音频是感知数据的重要形式,可以通过浏览器 API 进行访问。如何识别语音和其他声音的内容和含义?值得注意的是,卷积不仅可用于计算机视觉,而且还可以极大地帮助与音频相关的机器学习。
在本章中,您将看到如何使用类似于为 MNIST 构建的 convnet 来解决相对简单的音频任务。任务是将语音录音的简短片段分类为 20 个左右的单词类别。该任务比您在诸如 Amazon Echo 和 Google Home 之类的设备中可能看到的那种语音识别更为简单。这些语音识别系统比本示例中使用的词汇量更大的词汇量。同样,他们处理由多个连续发音的单词组成的连接语音,而我们的示例处理一次发音的单词。因此,我们的示例没有资格作为“语音识别器”,而是更准确地描述为“单词识别器”或“语音命令识别器”。但是,我们的示例仍然具有实际用途(例如,免提用户界面和可访问性功能)。同样,此示例中体现的深度学习技术实际上构成了更高级的语音识别系统的基础[70]。
# 4.4.1 频谱图:将声音表示为图像
像在任何深度学习应用程序中一样,如果您想了解模型的工作原理,则需要首先了解数据。要了解音频卷积网络是如何工作的,我们首先需要看一下如何将声音表示为张量。回忆高中物理时,声音是气压变化的模式。麦克风拾取气压变化并将其转换为电信号,然后可以通过计算机的声卡将其数字化。现代的 Web 浏览器具有 WebAudio API,该 API 与声卡对话并提供对数字化音频信号的实时访问(在用户许可的情况下)。因此,从 JavaScript 程序员的角度来看,声音是实数值数组。在深度学习中,此类数字数组通常表示为一维张量。
一些读者可能会想知道:我们看到的那种卷积如何处理一维张量?他们不是应该对至少二维的张量进行操作吗?convnet 的关键层(包括 conv2d 和 maxPooling2d)利用 2D 空间中的空间关系。事实证明,声音可以表示为一种特殊的图像形式,称为频谱图。频谱图不仅可以将卷积应用于声音,而且还具有深度学习以外的理论依据。
如图 4.12 所示,频谱图是 2D 数字数组,可以将其显示为与 MNIST 图像几乎相同的灰度图像。的水平尺寸是时间,垂直一个是频率。频谱图的每个垂直切片都是短时间窗口内的声音频谱。频谱是将声音分解为不同的频率成分,可以将其大致理解为不同的“音高”。正如可以将棱镜将光分为多种颜色一样,可以通过称为傅立叶变换的数学运算将声音分解为多种频率。因此,简而言之,频谱图描述了声音的频率内容如何在多个连续的短时间窗口(通常为 20 毫秒)内变化。
由于以下原因,频谱图是声音的合适表示。首先,它节省了空间:频谱图中的浮点数数量通常比原始波形中的浮点数数量少几倍。其次,从广义上讲,声谱图与听力在生物学中的工作方式相对应。内耳内部称为耳蜗的解剖结构实质上执行了傅里叶变换的生物学形式。它将声音分解成不同的频率,然后由不同的听觉神经元集合拾取。第三,语音的声谱图表示使不同类型的语音更易于彼此区分。图 4.12 中的示例语音频谱图显示了这一点:元音和辅音在其频谱图中均具有不同的定义模式。几十年前,在机器学习被广泛采用之前,从事语音识别的人们实际上是在尝试手工制作规则,以从频谱图中检测出不同的元音和辅音。深度学习为我们节省了手工制作的麻烦。
# 图 4.12 语音“zero”和“yes”的示例频谱图。频谱图是声音的联合时频表示。您可以将频谱图视为以图像表示的声音。沿时间轴的每个切片(即图像的一列)都是时间上的一小段瞬间(帧);沿着频率轴的每个切片(即图像的一行)对应于特定的狭窄频率范围(音高)。图像每个像素处的值表示给定时间点在给定频率仓中声音的相对能量。绘制以上的频谱图,使较深的灰色阴影对应于更高的能量。不同的语音具有不同的定义特征。例如,诸如“ z”和“ s”之类的稳定辅音的特征在于准稳态能量集中在 2-3 kHz 以上的频率上。元音(如“ e”和“ o”)的特征在于频谱低端(❤️ kHz)的水平条纹(即能量峰)。这些能量峰值在声学中称为“共振峰”。不同的元音具有不同的共振峰频率。不同的语音的所有这些鲜明特征都可以被深层的卷积网络用于单词识别。
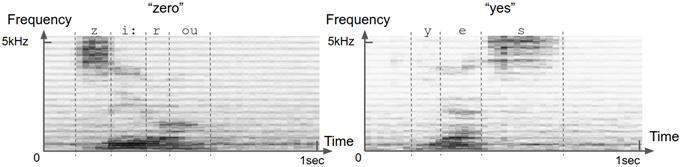 让我们停下来思考一下。查看图4.1中的MNIST图像和图4.12中的语音声谱图,您应该能够理解两个数据集之间的相似性。这两个数据集都包含2D特征空间中的模式,一对训练有素的眼睛应该能够分辨出这些模式。这两个数据集在特征的详细位置,大小和细节上均显示出一定的随机性。最后,两者都是多类别分类任务。尽管MNIST包含10种可能的类别,但我们的语音命令数据集却包含20种(从“0”到“9” 的十个数字, “up”, “down”, “left”, “right”, “go”, “stop”, “yes”, “no” ,以及“未知”字词和背景噪音类别)。正是由于数据集本质上的这些相似性,使卷积适合于语音命令识别任务。
让我们停下来思考一下。查看图4.1中的MNIST图像和图4.12中的语音声谱图,您应该能够理解两个数据集之间的相似性。这两个数据集都包含2D特征空间中的模式,一对训练有素的眼睛应该能够分辨出这些模式。这两个数据集在特征的详细位置,大小和细节上均显示出一定的随机性。最后,两者都是多类别分类任务。尽管MNIST包含10种可能的类别,但我们的语音命令数据集却包含20种(从“0”到“9” 的十个数字, “up”, “down”, “left”, “right”, “go”, “stop”, “yes”, “no” ,以及“未知”字词和背景噪音类别)。正是由于数据集本质上的这些相似性,使卷积适合于语音命令识别任务。
但是,两个数据集之间也存在一些明显的差异。首先,语音命令数据集中的录音有些嘈杂。在图 4.12 的示例频谱图中,可以看到不属于语音的暗像素斑点。其次,语音命令数据集中的每个声谱图的尺寸为 43 _ 232,与单个 MNIST 图像的 28 _ 28 尺寸相比明显更大。频谱图的大小在时间和频率维度之间是不对称的。这些差异将由我们将在音频数据集上使用的卷积网络反映出来。
定义和训练语音命令 convnet 的代码位于 tfjs-models 存储库中。您可以使用以下命令访问代码:
git clone https://github.com/tensorflow/tfjs-models.git
cd speech-commands/training/browser-fft
模型的创建和编译封装在 model.ts 中的 createModel 函数中。
# 代码 4.8 Convnet 用于对语音命令的频谱图进行分类
function createModel(inputShape: tf.Shape, numClasses: number) {
const model = tf.sequential();
model.add(
tf.layers.conv2d({
filters: 8,
kernelSize: [2, 8],
activation: 'relu',
inputShape
})
);
model.add(tf.layers.maxPooling2d({ poolSize: [2, 2], strides: [2, 2] }));
model.add(tf.layers.conv2d({ filters: 32, kernelSize: [2, 4], activation: 'relu' }));
model.add(tf.layers.maxPooling2d({ poolSize: [2, 2], strides: [2, 2] }));
model.add(tf.layers.conv2d({ filters: 32, kernelSize: [2, 4], activation: 'relu' }));
model.add(tf.layers.maxPooling2d({ poolSize: [2, 2], strides: [2, 2] }));
model.add(tf.layers.conv2d({ filters: 32, kernelSize: [2, 4], activation: 'relu' }));
model.add(tf.layers.maxPooling2d({ poolSize: [2, 2], strides: [1, 2] }));
model.add(tf.layers.flatten());
model.add(tf.layers.dropout({ rate: 0.25 }));
model.add(tf.layers.dense({ units: 2000, activation: 'relu' }));
model.add(tf.layers.dropout({ rate: 0.5 }));
model.add(tf.layers.dense({ units: numClasses, activation: 'softmax' }));
model.compile({
loss: 'categoricalCrossentropy',
optimizer: tf.train.sgd(0.01),
metrics: ['accuracy']
});
model.summary();
return model;
}
我们的音频 convnet 的拓扑看起来很像 MNIST convnet。顺序模型从 conv2d 层与 maxPooling2d 层几个重复模块开始。模型的卷积池部分在平坦层结束,在平坦层后面添加了多层感知器(MLP)。MLP 具有两个密集层。隐藏的密集层具有 relu 激活,而最后一层(输出)由适合分类任务的 softmax 激活。编译该模型以使用 categoricalCrosssentropy 作为损失函数,并在训练和评估期间发出准确性度量。这与 MNIST 卷积网络完全相同,因为两个数据集都涉及多类别分类。音频卷积网络还显示出与 MNIST 有所不同的一些有趣之处。特别是,conv2d 层的 kernelSize 属性是矩形(例如[2,8])而不是正方形。选择这些值以匹配频谱图的非正方形形状,这些频谱图的频率维度大于时间维度。
要训练模型,您需要首先下载语音命令数据集。该数据集源自 Google Brain 团队的工程师 Pete Warden 收集的语音命令数据集[71]。它已转换为浏览器专用的频谱图格式。
curl -fSsL https://storage.googleapis.com/learnjs-data/speech-commands/speech-commands-data-v0.02-browser.tar.gz -o speech-commands-data-v0.02-browser.tar.gz &&
tar xzvf speech-commands-data-v0.02-browser.tar.gz
这些命令将下载并提取语音命令数据集的浏览器版本。提取数据后,您可以使用以下命令开始训练过程:
Yarn
yarn train speech-commands-data-browser/ /tmp/speech-commands-model/
yarn train 命令的第一个参数指向训练数据的位置。以下参数指定了将保存模型的 JSON 文件以及权重文件和元数据 JSON 文件的路径。就像我们训练增强型 MNIST 卷积网络一样,音频卷积网络的训练发生在 tfjs-node 中,有可能利用 GPU。因为数据集和模型的大小大于 MNIST 卷积,所以训练将花费更长的时间(约数小时)。如果您拥有 CUDA GPU,并稍微更改命令以使用 tfjs-node-gpu 代替默认的 tfjs-node(仅在 CPU 上运行),则可以大大提高培训速度。为此,只需在上面的命令中添加标志“ --gpu”,即
yarn train --gpu speech-commands-data-browser/ /tmp/speech-commands-model/
训练结束后,模型应达到大约 94%的最终评估(测试)准确性。 训练后的模型将保存在上述命令参数所指定的路径上。就像我们使用 tfjs-node 训练的 MNIST 卷积网络一样,保存的模型可以加载到浏览器中进行投放。但是,您需要熟悉 WebAudio API,才能从麦克风获取数据并将其预处理为模型可以使用的格式。为方便起见,我们编写了一个包装器类,该类不仅加载经过训练的音频卷积网络,而且还负责数据的提取和预处理。如果您对音频数据输入管道的机制感兴趣,则可以在 tfjs-model git 存储库中的“speech-commands/src”文件夹下研究基础代码。可通过 npm 以名称“ @ tensorflow-models / speech-commands”使用包装器。下面的代码清单显示了包装器类如何用于在浏览器中执行语音命令字的在线识别的示例。 在 tfjs-models 存储库的 speech-commands / demo 文件夹中,您可以找到有关如何使用该软件包的较简单的示例。要克隆并运行演示,请在 speech-commands 目录下运行以下命令:
git clone https://github.com/tensorflow/tfjs-models.git
cd tfjs-models/speech-commands
yarn && yarn publish-local
cd demo
yarn && yarn link-local && yarn watch
yarn watch 命令将在您的默认 Web 浏览器中自动打开一个新选项卡。为了查看语音命令识别器的运行情况,请确保您的机器已准备好麦克风(大多数笔记本电脑都准备好了)。每次识别词汇表中的单词时,它将实时的与包含该单词的频谱图一起显示在屏幕上。因此,这是由 WebAudio API 和深度卷积神经网络提供支持的基于浏览器的单词识别。当然,它没有能力识别带有语法的关联语音。这将需要能够处理顺序信息的其他类型的神经网络构造块的帮助。我们将在第 8 章中访问这些内容。
# 代码 4.9 @ tenosrflow-models / speech-commands 模块的用法示例
import * as SpeechCommands from '@tensorflow-models/speech-commands';
const recognizer = SpeechCommands.create('BROWSER_FFT');
console.log(recognizer.wordLabels());
recognizer.listen(
result => {
let maxIndex;
let maxScore = -Infinity;
result.scores.forEach((score, i) => {
if (score > maxScore) {
maxIndex = i;
maxScore = score;
}
});
console.log(`Detected word ${recognizer.wordLabels()[maxIndex]}`);
},
{
probabilityThreshold: 0.75
}
);
setTimeout(() => recognizer.stopStreaming(), 10e3);