与我交流

# 4.2 你的第一个卷积神经网络
给定图像数据和标签的表示形式,我们知道求解 MNIST 数据集的神经网络应该采用什么样的输入,以及它应该生成什么样的输出。神经网络的输入是 NHWC 格式形状的张量[null,28,28,1]。输出是形状的张量[null,10],其中第二维度对应于十个可能的数字。这是多类分类目标的规范一次热编码。这和我们在第三章的虹膜例子中看到的虹膜花种类的热编码是一样的。利用这些知识,我们可以深入研究卷积网络(简称 convnets)的细节,即 MNIST 等图像分类任务的选择方法。这个名字听起来可能很吓人。其实这只是一种数学运算,我们将详细解释。
代码位于 tfjs 示例的 mnist 文件夹中。与前面的示例一样,您可以通过以下方式访问和运行代码:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/mnist
yarn && yarn watch
下面的代码清单 4.1 摘自 mnist 示例中的 main index.js 代码文件。它是一个函数,用来创建我们用来解决 MNIST 问题的 convnet。这个序列模型(7)中的层数明显大于我们看到的示例(介于 1 到 3 层之间)。
# 代码清单 4.1 为 MNIST 数据集定义卷积模型。
function createConvModel() {
const model = tf.sequential();
model.add(
tf.layers.conv2d({
inputShape: [IMAGE_H, IMAGE_W, 1],
kernelSize: 3,
filters: 16,
activation: 'relu'
})
);
model.add(tf.layers.maxPooling2d({ poolSize: 2, strides: 2 }));
model.add(
tf.layers.conv2d({
kernelSize: 3,
filters: 32,
activation: 'relu'
})
);
model.add(tf.layers.maxPooling2d({ poolSize: 2, strides: 2 }));
model.add(tf.layers.flatten());
model.add(tf.layers.dense({ units: 64, activation: 'relu' }));
model.add(tf.layers.dense({ units: 10, activation: 'softmax' }));
model.summary();
return model;
}
# 图 4.2 清单 4.1 中的代码构造的简单 convnet 的体系结构的概览图。在这个图中,为了便于说明,图像和中间张量的大小比清单 4.1 定义的模型中的实际大小要小。卷积核的大小也是如此。还要注意,此图显示了每个中间 4D 张量中的单个通道,而实际模型中的中间张量具有多个通道。
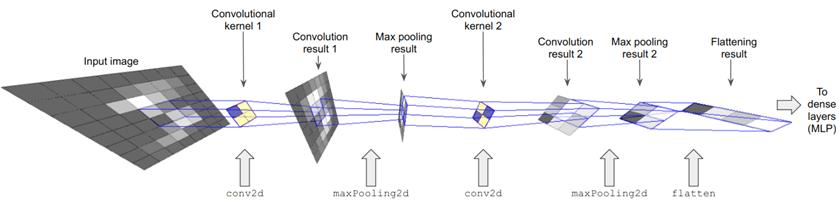
由上述代码构建的序列模型由七层组成,通过add()方法调用逐个创建。在我们检查每一层执行的详细操作之前,让我们看看模型的总体架构,如图4.2所示。如图所示,模型的前五层包括conv2d-maxPooling2d层组的重复模式,然后是flatten层。conv2d-maxPooling2d图层组是特征提取的工作部分。每层都将输入图像转换为输出。conv2d层通过卷积核进行操作,卷积核在输入图像的高度和宽度维度上“滑动”。在每个滑动位置,它与输入像素相乘,然后求和并通过非线性反馈。这将在输出图像中生成一个像素。maxPooling2d层以类似的方式运行,但没有内核。将输入的图像数据通过连续的卷积层和池,我们得到的张量在特征空间中变得越来越小,越来越抽象。最后一个池层的输出通过展平变换成一维张量,最后作为密集层的输入(图中未显示)。
因此,您可以将 convnet 看作是一个多层感知器(MLP),它建立在卷积和池预处理之上。MLP 与波士顿房屋和网络钓鱼检测问题的相同点都是由具有非线性激活的密集层组成。convnet 的不同之处在于,MLP 的输入是级联 conv2d 和 maxPooling2d 层的输出。这些层专门为图像输入设计,以从中提取有用的特征。这种结构是通过多年的神经网络研究发现的:它比直接将图像的像素值输入 MLP 有更高的精度。
通过对 MNIST convnet 的深入理解,现在让我们看看模型层的内部工作。
# 4.2.1 conv2d 层
第一层是 conv2d 层,它执行 2D 卷积。这是你在这本书中看到的第一个卷积层。它是做什么的?conv2d 是一种图像到图像的变换,它将一个 4D(NHWC)图像张量变换成另一个 4D 图像张量,其中具有不同的高度、宽度和通道数。(conv2d 对 4D 张量进行操作似乎有些奇怪,但请记住,有两个额外的维度,一个用于批处理示例,另一个用于通道。)直观地说,它可以理解为一组简单的“Photoshop 过滤器”[66],包括图像模糊和锐化等效果。这些效果是通过二维卷积来实现的,其中包括在输入图像上滑动一小块像素(称为卷积核,或简单地称为核)。在每个滑动位置,内核与输入图像的部分重叠,逐像素相乘。然后逐像素的乘积相加,形成结果图像中的像素。
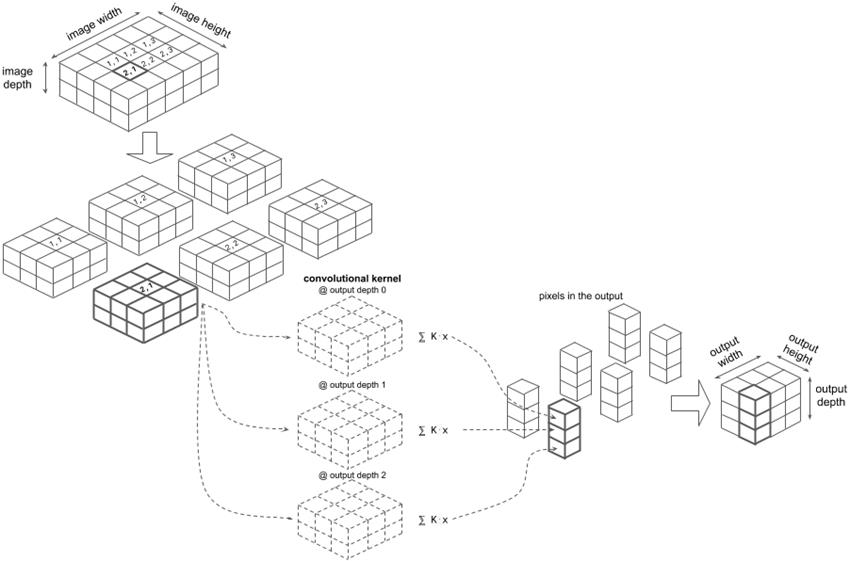
# 图 4.3 举例说明 Conv2D 层的工作原理。为简单起见,假设输入张量(左上角)仅包含一个图像,因此是三维张量。它的尺寸是高度、宽度和深度(颜色通道)。为了简单起见,省略了批处理维度。为了简单起见,输入图像张量的深度设置为 2。注意,图像的高度 4 和宽度 5 远小于典型真实图像的高度和宽度。深度 2 小于更典型的值 3 或 4(例如,对于 RGB 或 RGBA)。假设 Conv2D 层的 filters 属性(过滤器数量)为 3,kernelSize 为[3,3],滑动距离为[1,1],执行 2D 卷积的第一步是通过高度和宽度维度滑动并提取原始图像的部分。图中每个面的高度为 3,宽度为 3,与图层的过滤大小相匹配;它的深度也与原始图像相同。在第二步中,在每个 3×3×2 块和卷积核(即“滤波器”)之间计算“点积”。有关每个点积操作的详细信息,请参见下面的图 4.4。内核是一个 4D 张量,由三个 3D 过滤器组成。对于这三个滤波器,带滤波器的图像块之间可进行点积相乘。将图像块与滤波器逐像素相乘,求和得到输出张量中的一个像素。因为内核中有三个过滤器,所以每个图像块都转换为 3 个像素的堆栈。点积操作在所有的图像块上执行,结果 3 个像素的堆栈合并为输出张量,形状为[2,3,3]。
与密集层相比,conv2d 层具有更多的配置参数。kernelSize 和 filters 是 conv2d 层的两个关键参数。为了理解它们的含义,我们需要描述二维卷积是如何在概念层面上工作的。
图 4.3 更详细地说明了二维卷积。这里我们假设输入图像(左上角)张量由一个简单的例子组成,这样我们可以很容易地在纸上画出来。我们假设 conv2d 操作配置为 kernelSize=3 和 filters=3。由于输入图像有两个颜色通道(只是为了说明,通道的数目有些不寻常),因此核心是形状为 3D 张量[3,3,2,3]。前两个数字(3 和 3)是内核的高度和宽度,由 kernelSize 决定。第三维度(2)是输入通道的数量。什么是第四维度(3)?它是滤波器的数目,是 conv2d 输出张量的最后一个维数。如果输出被视为图像张量(这是一种完全有效的方法!),则滤波器可以理解为输出中的通道数。与输入图像不同,输出张量中的通道实际上与颜色无关。相反,它们表示从训练数据中学习到的输入图像的不同视觉特征。例如,一些滤光片可能对特定方向上亮区和暗区之间的直线边界敏感,而另一些滤光片可能对由棕色形成的角敏感,等等。稍后再谈。
上面提到的“滑动”动作表示为从输入图像中提取小块。每个小块的高度和宽度都等于 kernelSize(在本例中为 3)。由于输入图像的高度为 4,因此沿高度维度只有 2 个可能的滑动位置,因为我们需要确保 33 窗口不超出输入图像的边界。类似地,输入图像的宽度(5)为我们提供了沿宽度维度的 3 个可能的滑动位置。因此,我们最终提取了 23=6 个图像块。
在每个滑动窗口位置,都会发生“点积”操作。回想一下卷积核的形状是[3,3,2,3]。我们可以将最后一个维度上的 4D 张量分解成三个独立的 3D 张量,每个张量的形状都是[3,3,2],如图 4.3 中的散列线所示。我们取图像块和其中一个三维张量,将它们相乘,逐像素相乘,然后将所有 332=18 的值求和,得到输出张量中的一个像素。下面的图 4.4 更详细地说明了点积步骤。图像块和卷积核的切片形状完全相同不是巧合-我们根据核的形状提取图像块!这个乘法和加法操作对内核的所有三个部分都重复,它给出一组三个数字。然后对剩余的图像补片重复此点积操作,这将给出图中三个立方体的六列。最后将这些列组合起来形成输出,其 HWC 形状为[2、3、3]。
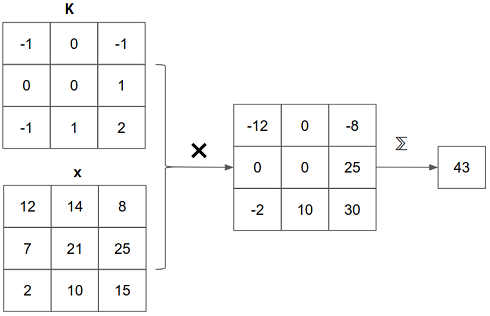
# 图 4.4 二维卷积运算中的点积(即乘法和加法)运算的图示,如图 4.3 所示。为了便于说明,假设图像块(x)仅包含一个颜色通道。图像块的形状为[3,3,1],即与卷积核片的大小(K)相同。第一步是逐元素乘法,它产生另一个[3,3,1]张量。新张量的元素被加在一起(用 ∑ 表示),sume 就是结果。
 与密集层一样,conv2d层也有一个偏移项,该偏移项被添加到卷积的结果中。此外,conv2d层通常被配置为具有非线性激活功能。在这个例子中,我们使用relu。回想一下,在第3.1.1.2节中,叠加两个没有非线性的致密层相当于使用一个致密层,类似的适用于conv2d层:在没有非线性激活的情况下叠加两个这样的层在数学上等同于使用具有更大内核的单个conv2d层,因此是构造convnet的低效方法,应该避免。
与密集层一样,conv2d层也有一个偏移项,该偏移项被添加到卷积的结果中。此外,conv2d层通常被配置为具有非线性激活功能。在这个例子中,我们使用relu。回想一下,在第3.1.1.2节中,叠加两个没有非线性的致密层相当于使用一个致密层,类似的适用于conv2d层:在没有非线性激活的情况下叠加两个这样的层在数学上等同于使用具有更大内核的单个conv2d层,因此是构造convnet的低效方法,应该避免。
呼!这是关于 conv2d 层如何工作的详细信息。让我们退一步,看看 conv2d 实际实现了什么。简而言之,它是将输入图像转换为输出图像的一种特殊方法。与输入图像相比,输出图像通常具有更小的高度和宽度。大小的减少取决于内核大小配置。输出图像可能具有比输入更少或更多或相同的通道,这由滤波器配置决定。
所以 conv2d 是一个图像到图像的转换。conv2d 变换的两个关键特性是局部性和参数共享。
- 局部性是指输出图像中给定像素的值仅受输入图像的一小块影响,而不受输入图像中所有像素的影响的特性。这个补丁的大小是 kernelSize。这就是使 conv2d 不同于密集层的原因:在密集层中,每个输出元素都受每个输入元素的影响。换言之,输入元素和输出元素在密集层中“密集连接”(因此得名)。所以我们可以说 conv2d 层是“稀疏连接的”。当密集层在输入中学习全局模式时,卷积层学习局部模式,即内核的小窗口中的模式。
- 参数共享是指输出像素 A 受其输入局部的影响与输出像素 B 受其输入局部影响的方式相同。这是因为每个滑动位置的点积使用相同的卷积核(图 4.3)。
由于局部性和参数共享,conv2d 层就所需参数的数量而言,是一个高效的图像到图像的变换。特别地,卷积核的大小不随输入图像的高度或宽度而改变。回到清单 4.1 中的第一个 conv2d 层,内核的形状是[kernelSize,kernelSize,1,filter](即[5,5,1,8]),不管输入的 MNIST 图像是 2828 还是更大,其总共仍有 5518=200 个参数。第一个 conv2d 层的输出具有[24、24、8]的形状(省略批次维度)。因此,conv2d 层将一个由 28281=784 个元素组成的张量转换为另一个由 24248=4608 个元素组成的张量。如果我们用密集层实现这个转换,需要多少参数?答案是 784*4608=3612672(不包括偏差),大约是 conv2d 层的 18000 倍!该思想实验证明了卷积层的有效性。
conv2d 的局部性和参数共享的优点不仅在于它的效率,而且在于它模仿(以松散的方式)生物视觉系统的工作方式。借鉴视网膜中的神经元,每一个神经元只受眼睛视觉场中一小块被称为感受视野区域的影响。位于视网膜不同位置的两个神经元对各自感受野中的光模式的反应几乎相同,这类似于 conv2d 层中的参数共享。更重要的是,conv2d 层被证明对计算机视觉问题很有效,正如我们很快在这个 MNIST 示例中预测的那样。conv2d 是一个简洁的神经网络层,它拥有所有的功能:效率、准确性和与生物学的相关性。难怪它在深度学习中被如此广泛地应用。
# 4.2.2 maxPooling2d 层
conv2d 层之后,让我们看看序列模型中的下一层。它是一个 maxPooling2d 层。与 conv2d 一样,maxPooling2d 也是一种图像到图像的转换。但是,与 Purv2D 相比,maxPooling2d 变换更简单。如下面的图 4.5 所示,它简单地计算小图像块中的最大像素值,并将它们用作输出中的像素值。定义和添加 maxPooling2d 层的代码是:
model.add(tf.layers.maxPooling2d({poolSize:2,strips:2}))
在这种特殊情况下,由于指定的 poolSize 值为[2,2],图像的高度和宽度为 2×2。沿着两个维度,每两个像素提取一个面片。这些图像块之间的间距来自于使用的跨距值:[2,2]。结果,HWC 形状为[12、12、8]的输出图像是输入图像(形状为[24、24、8])的一半高度和一半宽度,但是具有相同数量的通道。
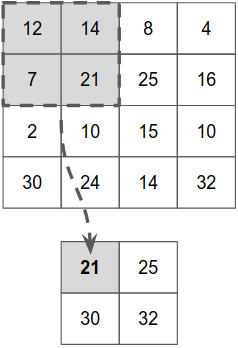
# 图 4.5 举例说明 maxPooling2D 层是如何工作的。本例使用一个很小的 4*4 图像,并假设 MaxPooling2D 层 poolSize 为[2,2],跨步为[2,2]。深度维度未显示,最大池操作在各个维度上独立进行。
maxPooling2d层在convnet中有两个主要用途。首先,它使convnet对输入图像中关键特征的精确位置不太敏感。例如,不管它是从28x28输入图像的中心向左还是向右移动(或向上或向下移动),我们希望都能够识别数字“8”,这称为位置不变性的特性。要了解maxPooling2d层如何增强位置不变性,需要清楚在maxPooling2d操作的每个图像块中,只要在这个块中,最亮的像素在哪里并不重要。不可否认,单个maxPooling2d层只能使convnet对移位不敏感,因为它的池窗口是有限的。然而,当在同一个convnet中使用多个maxPooling2d层时,它们协同工作以获得更大的位置不变性。这正是在我们的MNIST模型中,以及在几乎所有实际的convnets中所做的,它包含两个maxPooling2d层。作为思维实验,考虑两个conv2d层(称为conv2d_1和conv2d_2)直接堆叠在一起而没有中间maxPooling2d层时会发生什么。假设两个conv2d层中的每个层的内核大小为3,那么conv2d_2的输出张量中的每个像素是conv2d_1原始输入中5×5区域的函数。我们可以说每个“神经元”conv2有一个大小为5×5的感受视野。当两个conv2d层之间有一个中间的maxPooling2d层时(MNIST convnet就是这种情况),会发生什么?conv2d_2神经元的感受野变大:11×11。这当然是由于池操作。当多个maxPooling2d层存在于convnet中时,更高层次的层可以具有宽的接收场和位置不变性。总之,他们能看得更远!
其次,maxPooling2d 层还缩小了输入张量的高度和宽度维度的大小,显著减少了后续层和整个 convnet 中所需的计算量。例如,来自第一 conv2d 层的输出具有形状为[26、26、16]的输出张量。通过 maxPooling2d 层后,张量形状变为[13,13,16],从而将张量元素的数量减少了 4 倍。convnet 包含另一个 maxPooling2d 层,它进一步缩小了后续层中权重的大小以及这些层中元素级数学运算的数量。
# 4.2.3 重复卷积和合并
第一个 maxPooling2d 层之后,让我们将注意力集中在 convnet 的下两个层上,由代码清单 4.1 中的这些行定义:
model.add(tf.layers.conv2d({ kernelSize: 3, filters: 32, activation: 'relu' }));
model.add(tf.layers.maxPooling2d({ poolSize: 2, strides: 2 }));
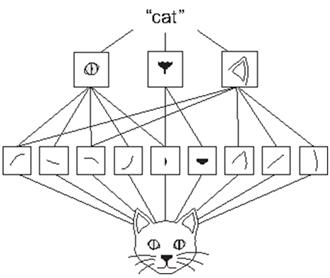
这两个层是前两个层的完全重复(除了 conv2d 层在其过滤器配置中具有更大的值并且不具有 inputShape 字段)。这种由卷积层和极化层组成的几乎重复的“模体”在 convnets 中常见。它在 convnet 中扮演着关键的角色:特征的分层提取。为了理解它的含义,可以考虑一个训练过的 convnet,它的任务是对图像中的动物进行分类。在 convnet 的早期阶段,卷积层中的滤波器(即 channel)可以编码诸如直线、曲线和角等低级几何特征。这些低级特征转化为更复杂的特征,如猫的眼睛、鼻子和耳朵。在 convnet 的顶层,一个层可能有对整个 cat 的存在进行编码的过滤器。级别越高,表示越抽象,从像素级值中移除的特征越多。但是,这些抽象的特征正是 convnet 任务实现良好精度所需要的,例如,在图像中时检测出猫。此外,这些特征不是手工制作的,而是通过有监督的学习并以自动方式从数据中提取的。这是一个典型的有代表性的例子,我们曾在第一章把它描述为深层学习的层-层转换。
# 图 4.6 以猫的图像为例,利用 convnet 从输入图像中分层提取特征。注意,在这个例子中,神经网络的输入在底部,输出在顶部。
 ## 4.2.4扁平层和致密层
当输入张量通过两组conv2d-maxPooling2d变换后,它变成HWC形状的张量[4,4,16](没有批处理维度)。convnet中的下一层是扁平层。此层是先前的conv2d-maxPooling2d层和序列模型的以下层之间形成的一个桥层。
## 4.2.4扁平层和致密层
当输入张量通过两组conv2d-maxPooling2d变换后,它变成HWC形状的张量[4,4,16](没有批处理维度)。convnet中的下一层是扁平层。此层是先前的conv2d-maxPooling2d层和序列模型的以下层之间形成的一个桥层。
扁平层的代码很简单,因为构造函数不需要任何配置参数。
model.addtf.layers.flatten(());
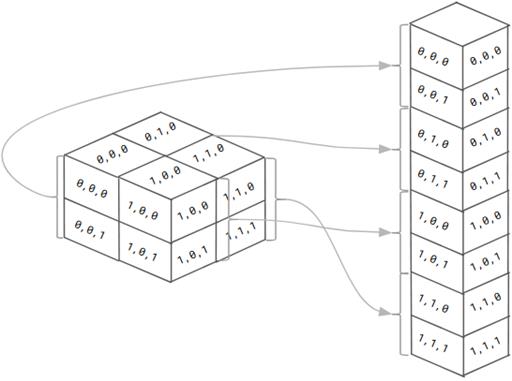
扁平层将多维张量“压缩”为一维张量,从而保持元素的总数。在我们的例子中,形状为[3,3,32]的 3D 张量被展平为 1D 张量[288](没有批次维度)。挤压操作的一个明显问题是如何对元素排序,因为原始三维空间中没有内在的顺序。答案是:我们对元素进行排序,这样,如果你沿着展开的一维张量中的元素向下看,看看它们的原始索引(来自三维张量)如何变化,最后一个索引变化最快,倒数第二个索引变化第二快,以此类推,而第一个索引变化最慢。如下图 4.7 所示。
# 图 4.7 扁平层工作原理的简单说明,假设为三维张量输入。为了简单起见,我们让每个维度都有一个 2 的小尺寸。元素的索引显示在表示元素的立方体的“面”上。该层将三维张量转换为一维张量,同时保留元素总数。展平的一维张量中元素的顺序是这样的,当您向下观察输出的一维张量的元素并检查它们在输入张量中的原始索引时,会发现最后一个维度是变化最快的维度.
 扁平层在我们的convnet中有什么作用?它为随后的致密层奠定了基础。正如我们在第2章和第3章中了解到的,由于其工作原理(第2.1.4节),稠密层通常以1D张量(不包括批次维度)作为输入。
###### 清单4.1中接下来的两行代码向convnet添加了两个密集层:
```js
model.add(tf.layers.dense({units: 64, activation: 'relu'}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'}));
```
扁平层在我们的convnet中有什么作用?它为随后的致密层奠定了基础。正如我们在第2章和第3章中了解到的,由于其工作原理(第2.1.4节),稠密层通常以1D张量(不包括批次维度)作为输入。
###### 清单4.1中接下来的两行代码向convnet添加了两个密集层:
```js
model.add(tf.layers.dense({units: 64, activation: 'relu'}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'}));
```
为什么是两层而不是一层?与我们在第3章中看到的波士顿住房和网络钓鱼URL检测示例相同的原因:添加具有非线性激活的层会增加网络的容量。实际上,您可以将convnet看作是由两个模型堆叠在一起:
- 包含 conv2d、maxPooling2d 和 flatten 层的模型,用于从输入图像中提取视觉特征。
- 一种多层感知器(MLP),具有两个密集层,以提取的特征作为输入,并基于它进行数字类预测,这就是这两个密集层的本质。 在深度学习中,许多模型都利用了特征提取层的这种模式,然后最终预测使用 mlp。在本书的其余部分中,我们将看到更多这样的例子,从音频信号分类器到自然语言处理。
# 4.2.5 训练 Convnet
既然我们已经成功地定义了 convnet 的拓扑结构,下一步就是训练 convnet 并评估训练的结果。这就是下面清单 4.2 中的代码的用途。
# 代码清单 4.2 训练和评估 MNIST convnet。
const optimizer = 'rmsprop';
model.compile({
optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy']
});
const batchSize = 320;
const validationSplit = 0.15;
await model.fit(trainData.xs, trainData.labels, {
batchSize,
validationSplit,
epochs: trainEpochs,
callbacks: {
onBatchEnd: async (batch, logs) => {
trainBatchCount++;
ui.logStatus(
`Training... (` +
`${((trainBatchCount / totalNumBatches) * 100).toFixed(1)}%` +
` complete). To stop training, refresh or close page.`
);
ui.plotLoss(trainBatchCount, logs.loss, 'train');
ui.plotAccuracy(trainBatchCount, logs.acc, 'train');
},
onEpochEnd: async (epoch, logs) => {
valAcc = logs.val_acc;
ui.plotLoss(trainBatchCount, logs.val_loss, 'validation');
ui.plotAccuracy(trainBatchCount, logs.val_acc, 'validation');
}
}
});
const testResult = model.evaluate(testData.xs, testData.labels);
这里的大部分代码都是关于在训练过程中更新 UI 的,例如,绘制丢失和精度值的变化。这些对于监控训练过程是有用的,但对于模型训练并不是绝对必要的。训练所必需的部分:
- trainData.xs(model.fit()的第一个参数);这包括表示为 NHWC 形状[N,28、28、1]的 4D 张量(批次示例的第一维)的输入 MNIST 图像,其中 N 是图像总数。
- trainData.labels(model.fit()的第二个参数):这包括输入标签,表示为形状为[N,10]的单次热编码 2D 张量。
- model.compile()调用中使用的损失函数 categoricalCrossentropy,适用于诸如 MNIST 之类的多分类问题。回想一下,我们在第 3 章中对虹膜花分类问题使用了相同的损失函数。
- model.compile()中指定的度量标准函数调用:“ accuracy”。假设预测是基于 convnet 输出的 10 个元素中的最大元素进行的,则此函数度量的示例中的一部分已正确分类。回想一下交叉熵损失和精度度量之间的区别:交叉熵是可微的,因此使基于反向传播的训练成为可能,而精度度量不可微,但更容易解释。
- model.fit()调用指定的 batchSize 参数。一般而言,使用较大的批次与较小的批次相比好处是,它对模型的权重产生了更一致且变化较小的渐变更新。但是批次大小越大,训练期间就需要更多的内存。您还应该记住,在给定相同数量的训练数据的情况下,较大的批次大小会导致每个时期的梯度更新数量较少。因此,如果您使用较大的批量,请确保相应地增加时期数,以免在训练过程中无意中减少了权重更新的次数。因此需要权衡。在这里,我们使用相对较小的批处理大小(64),因为我们需要确保该示例可在各种硬件上运行。与其他参数一样,您可以修改源代码并刷新页面,以试验使用不同批处理大小的效果。
- model.fit()调用中使用的 validateSplit。使用训练过程 trainData.xs 和 trainData.labels,以便在留有 15%的数据的训练期间进行验证。正如您在以前的非图像模型中所了解的那样,在训练期间监视验证损失和准确性很重要。它使您了解模型是否以及何时过度拟合。什么是过度拟合?简而言之,在这种状态下,模型对训练期间看到的数据的精细细节过于关注,以至于其在训练期间看不见的预测准确性受到负面影响。这是有监督的机器学习中的关键概念。在本书的后面(第 8 章),我们将在整章中专门介绍如何在本书的后面发现并消除过度拟合。
model.fit()是异步函数,因此如果后续操作依赖于 fit()调用的完成,则需要对其使用 await。这正是这里所做的,因为我们需要在模式训练后使用测试数据集对模型执行评估。使用 model.evaluate()方法执行计算,该方法是同步的。提供给 model.evaluate()的数据是 testData,其格式与上面提到的 trainData 相同,但示例数量较少。在 fit()调用期间,模型从未看到过这些示例,从而确保测试数据集不会泄漏到评估结果中,并且评估结果是对模型质量的客观评估。
# 图 4.8 MNIST convnet 的训练曲线。执行 10 个阶段的训练,每个时期由大约 800 批次组成。左:损失值。右:精度值。训练集和验证集的值由不同的颜色、线宽和标记符号显示。验证曲线包含的数据点比训练曲线少,因为与训练批不同,验证仅在每个时期结束时执行。
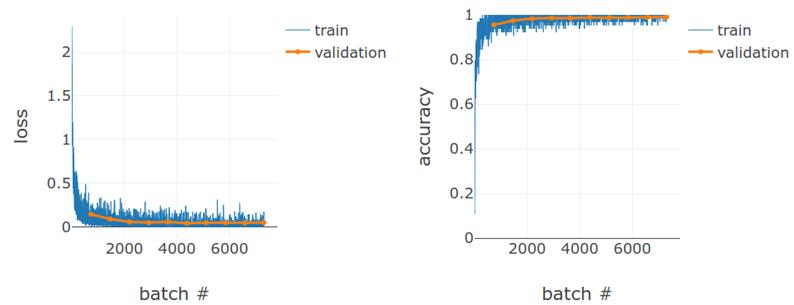 使用该代码,我们让模型训练10个阶段(在输入框中指定),给出损耗和精度曲线(图4.8)。如图所示,损失和精度也收敛到训练阶段的末尾。验证损失和准确度值与相应的训练值没有太大的偏差,这表明在这种情况下没有明显的过度拟合。最后一个model.evaluate()调用的精确度约为99.0%(由于权重的随机初始化和训练期间示例的隐式随机洗牌,每次运行得到的实际值略有不同)
使用该代码,我们让模型训练10个阶段(在输入框中指定),给出损耗和精度曲线(图4.8)。如图所示,损失和精度也收敛到训练阶段的末尾。验证损失和准确度值与相应的训练值没有太大的偏差,这表明在这种情况下没有明显的过度拟合。最后一个model.evaluate()调用的精确度约为99.0%(由于权重的随机初始化和训练期间示例的隐式随机洗牌,每次运行得到的实际值略有不同)
99.0%有多好?从实用的角度看,还可以,但肯定不是最先进的。随着卷积层的增多,通过增加卷积层和池层的数目以及模型中滤波器的数目,可以达到 99.5%的精度。但是,在浏览器中训练那些较大的 convnet 要花很长时间,因此在 Node.js 这样的资源约束较少的环境中进行训练是有意义的。我们将在第 4.3 节中向您展示如何做到这一点。
从理论上讲,记住 MNIST 是一个十向分类问题。所以概率水平(纯猜测)的准确率是 10%。99.0%比这好多了。但机会水平并不是很高。如何显示模型中 conv2d 和 maxPooling2d 层的值?如果我们坚持使用古老的致密层,我们会做得更好吗?
为了回答这个问题,我们可以做一个实验。js 中的代码包含另一个用于创建模型的函数,称为 createDenseModel。与我们在代码清单 4.1 中看到的函数不同,createDenseModel 创建了一个仅由扁平层和密集层组成的序列模型,也就是说,不使用我们在本章中学习到的新层类型。createDenseModel 确保在它创建的密集模型和我们刚刚训练过的神经网络之间的参数总数大致相等,即,大约为 33 K,因此它将是更公平的比较。
# 代码清单 4.3 MNIST 的只包括扁平层和稠密层的模型,用于与 convnet 进行比较。
function createDenseModel() {
const model = tf.sequential();
model.add(tf.layers.flatten({ inputShape: [IMAGE_H, IMAGE_W, 1] }));
model.add(tf.layers.dense({ units: 42, activation: 'relu' }));
model.add(tf.layers.dense({ units: 10, activation: 'softmax' }));
model.summary();
return model;
}
上述定义的模型结果如下:
Layer (type) Output shape Param #
=================================================================
flatten_Flatten1 (Flatten) [null,784] 0
_________________________________________________________________
dense_Dense1 (Dense) [null,42] 32970
_________________________________________________________________
dense_Dense2 (Dense) [null,10] 430
=================================================================
Total params: 33400
Trainable params: 33400
Non-trainable params: 0
_________________________________________________________________
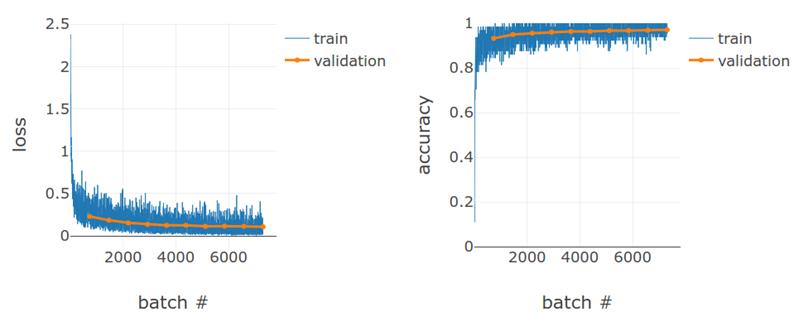
使用相同的训练配置,我们从非卷积模型获得如图 4.9 所示的训练结果。经过 10 个阶段的训练,最终得到的评价准确率为 97.0%。两个百分点的差异似乎很小,但就错误率而言,非卷积模型比 convnet 差 3 倍。作为实践练习,尝试通过增加 createDenseModel 函数中隐藏(第 1 个)密集层的 units 参数来增加非卷积模型的大小。您将看到,即使使用更大的尺寸,仅使用“密集”模型也不可能达到与 convnet 相同的精度。这向您展示了 convnet 的强大功能:通过参数共享和利用视觉特征的局部性,convnet 可以在参数数目等于或少于非卷积神经网络的情况下,在计算机视觉任务中获得更高的精度。
# 图 4.9 与图 4.8 相同,但对于 MNIST 问题的非卷积模型,它是由代码清单 4.3 中的 createDensModel 函数创建的。
 ## 4.2.6使用Convnet进行预测
现在我们有一个训练有素的convnet。我们如何使用它来对手写数字的图像进行真正的分类?首先,你需要掌握图像数据。通过多种方式可以将图像数据提供给TensorFlow.js模型。下面我们将列出它们并描述它们何时适用。
## 4.2.6使用Convnet进行预测
现在我们有一个训练有素的convnet。我们如何使用它来对手写数字的图像进行真正的分类?首先,你需要掌握图像数据。通过多种方式可以将图像数据提供给TensorFlow.js模型。下面我们将列出它们并描述它们何时适用。
# 从数组类型创建图像张量
在某些情况下,所需的图像数据已存储为 JavaScript 的数组类型。这就是我们关注的 tfjs 示例/mnist 示例中的情况。详细信息在 data.js 文件中。给定一个 float32 数组,表示一个长度的 MNIST(比如一个名为 imageDataArray 的变量),我们可以将其转换为模型所期望的 4D 张量:
let x = tf.tensor4d(imageDataArray, [1, 28, 28, 1]);
调用中的第二个参数指定要创建的张量的形状。这是必要的,因为 float32 数组(通常是 TypedArray)是一个平面结构,没有关于图像尺寸的信息。第一个维度的大小是 1,因为我们正在处理 imageDataArray 中的单个图像。与前面的例子一样,在训练、评估和推理过程中,无论只有一个图像还是有多个图像,模型总是期望批次维度。如果 float32 数组包含一批多个图像,也可以将其转换为一个张量,其中第一个维度的大小等于图像的数量:
let x = tf.tensor4d(imageDataArray, [numImages, 28, 28, 1]);
# tf.browser.fromPixels:从 HTML 图像、画布或视频元素获取图像张量
在浏览器中获取图像张量的第二种方法是对包含图像数据的 HTML 元素使用 TensorFlow.js 函数 tf.browser.fromPixels(),这包括 img、canvas 和 video 元素。
例如,假设一个网页包含一个 img 元素,定义为:
<img id="my-image" src="foo.jpg" />
用一行代码来表示图像元素的元素数据:
let x = tf.browser.fromPixels(document.getElementById('my-image')).asType('float32');
结果生成形状[height, width, 3],其中最后一个参数表示的 3 个通道是 RGB 颜色的编码。tf.browser.fromPixels()转化成整数 32 类型张量,asType 则是将其转化成浮点类型张量。高度和宽度决定图像元素的 大小。如果它与模型期望的高度和宽度不匹配,则可以更改 img 元素的 height 和 width 属性(当然,如果这不会使 UI 看起来很糟糕),也可以通过 tf.browser.fromPixels()中 TensorFlow.js 提供的两种图像调整大小方法 tf.image.resizeBilinear 和 tf.image.resizeNearestNeigbor 之一来调整张量大小:
x = tf.image.resizeBilinear(x, [newHeight, newWidth]);
tf.image.resizeBilinear 和 tf.image.resizeNearestNeighbor 具有相同的语法,但是它们使用两种不同的算法来调整图像大小。 前者使用双线性插值在新张量中形成像素值,而后者执行最近邻采样,并且通常比双线性插值计算强度低。
请注意,由 tf.browser.fromPixels()创建的张量不包含批处理尺寸。 因此,如果要将张量输入 TensorFlow.js 模型,则必须先对其进行尺寸扩展,例如,
x = x.expandDims();
expandDims()通常采用维度参数。但是在这种情况下,可以省略该参数,因为我们正在扩展第一个维度,这是该参数的默认值。
除 img 元素外,tf.browser.fromPixels()以相同的方式在画布和视频元素上工作。在画布元素上应用 tf.browser.fromPixels()有助于用户在 TensorFlow.js 模型使用内容之前交互式地更改画布内容的情况。例如,在一个在线手写识别应用程序或一个在线手绘形状识别应用程序。除静态图像外,在视频元素上应用 tf.browser.fromPixels()对于从网络摄像头获取逐帧图像数据很有用。这正是 Nikhil Thorat 和 Daniel Smilkov 在最初的 TensorFlow.js 的 Pac-Man 演示[68],以及 posenet 演示[69]以及其他许多使用网络摄像头的基于 TensorFlow.js 的网络应用程序中所做的工作。您可以在以下位置阅读源代码:https://github.com/tensorflow/tfjs-examples/tree/master/webcam-transfer-learning。
正如我们在前几章中所看到的那样,应格外小心,以免训练数据与推理数据之间出现偏斜(即不匹配)。在这种情况下,我们的 MNIST 卷积网络使用归一化到 0 到 1 范围内的图像张量进行训练。因此,如果 x 张量中的数据具有不同的范围(例如 0-255),这在基于 HTML 的图像数据中很常见,应该规范化数据,例如:
x = x.div(255);
数据在手,我们接下来便可以使用 model.predict()对数据进行预测了。
# 代码清单 4.4 使用训练好的 convnet 模型
const testExamples = 100;
const examples = data.getTestData(testExamples);
tf.tidy(() => {
const output = model.predict(examples.xs);
const axis = 1;
const labels = Array.from(examples.labels.argMax(axis).dataSync());
const predictions = Array.from(output.argMax(axis).dataSync());
ui.showTestResults(examples, predictions, labels);
});
编写该代码的前提是,用于预测的图像批处理已经在单个张量中可用,即 examples.xs。它的形状为[100,28,28,1](包括批处理尺寸),其中第一个尺寸反映了我们要对其进行预测的 100 张图像这一事实。 model.predict()返回形状为[100,10]的输出 2D 张量。输出的第一维对应于示例,而第二维对应于十个可能的数字。输出张量的每一行都包含分配给给定图像输入的十个数字的概率值。为了确定预测,我们需要逐个图像找出最大概率值的索引。这是通过以下行完成的:
const axis = 1;
const labels = Array.from(examples.labels.argMax(axis).dataSync());
argMax()函数返回沿给定轴的最大值的索引。在这种情况下,此轴是第二维,即 const 轴=1。argMax()的返回值是形状为[100,1]的张量。通过调用 dataSync(),我们将[100,1]形张量转换为长度为 100 的 Float32Array。然后 Array.from()将 Float32Array 转换为一个普通的 JavaScript 数组,该数组由 100 个介于 0 和 9 之间的整数组成。此预测数组的含义非常简单:这是模型对 100 个输入图像进行分类的结果。在 MNIST 数据集中,目标标签恰好与输出索引完全匹配。因此,我们甚至不需要将数组转换为字符串标签。预测数组由下一行使用,该行调用一个 UI 函数,该函数将分类结果与测试图像一起呈现(请参见下面的图 4.10)。
# 图 4.10 训练后模型进行预测的一些示例,与输入 MNIST 图像一起显示
