与我交流

# 4.3 浏览器外:使用 Node.js 更快地训练模型
在上一节中,我们在浏览器中训练了一个 convnet,它达到了 99.0%的测试准确性。在本节中,我们将创建一个功能更强大的卷积网络,该卷积网络将为我们提供更高的测试准确性,约为 99.5%。但是,提高准确性是要付出代价的:模型在训练和推理期间消耗了大量的内存和计算量。在训练过程中,成本的增加更为明显,因为训练涉及反向传播,与推理所需的正向运行相比,反向传播的计算量更大。在大多数 Web 浏览器环境中,较大的 convnet 太重且太慢而无法训练。
# 4.3.1 使用 tfjs-node 的依赖项并导入
进入 TensorFlow.js 的 Node.js 版本!它在后端环境中运行,不受任何资源限制(如浏览器选项卡的限制)影响。TensorFlow 的 Node.js 的 CPU 版本(以下简称 tfjs-node )直接使用以 C ++编写并由 TensorFlow 的主要 Python 版本使用的多线程数学运算。如果您的计算机上安装了支持 CUDA 的 GPU,则 tfjs-node 也可以使用以 CUDA 编写的 GPU 加速的数学内核,从而获得更大的速度提升。
增强型 MNIST 卷积网络的代码位于 tfjs-examples 的 mnist-node 目录中。如我们在示例中看到的,您可以使用以下命令来访问代码:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples / mnist-node
与前面的示例的不同之处在于 mnist-node 示例将在终端而不是 Web 浏览器中运行。要下载依赖项,请使用命令 yarn。
在 package.json 文件中可以看到依赖项@ tensorflow / tfjs-node。将@ tensorflow / tfjs-node 声明为依赖项后,yarn 会自动将 C ++共享库(在 Linux,Mac 或 Windows 系统上分别名为 libtensorflow.so,libtensorflw.dylib 或 libtensorflow.dll)下载到 node_modules 目录中供 TensorFlow.js 使用。
一旦 yarn 命令运行完毕,您可以使用以下命令开始模型训练:
node main.js
已经安装了 yarn 后,node 二进制文件在您的文件路径上可用(如果需要更多信息,请参阅附录 A3)。 上面的工作流程将使您能够在 CPU 上训练增强型 convnet。如果您的工作站和笔记本电脑内部具有启用 CUDA 的 GPU,您还可以在 GPU 上训练模型。涉及的步骤是:
- 为您的 GPU 安装正确版本的 NVIDIA 驱动程序
- 安装 NVIDIA CUDA 工具包。该库可在 NVIDIA GPU 系列上实现通用并行计算。
- 安装 CuDNN,这是 NVIDIA 基于 CUDA 构建的用于高性能深度学习算法的库(有关步骤 1-3 的更多详细信息,请参阅附录 A3)
- 在 package.json 中,将@ tensorflow / tfjs-node 依赖项替换为@ tensorflow / tfjs-node-gpu,但保持相同的版本号,因为这两个软件包同步发布。
- 再次运行 yarn,将下载共享库,其中包含供 TensorFlow.js 使用的 CUDA 数学运算。
- 在 main.js 中,用 require('@tensorflow/tfjs-node-gpu')替换 require('@tensorflow/tfjs-node');
- 再次开始训练 node main.js 如果正确完成了这些步骤,则您的模型将在 CUDA GPU 上运行,其训练速度通常是 CPU 版本(tfjs-node)可获得的速度的五倍。与在浏览器中训练相同模型相比,使用 tfjs-node 的 CPU 或 GPU 版本进行训练要快得多。
# 4.3.2 在 tfjs-node 中为 MNIST 训练增强的 convnet
一旦训练在 20 个时期内完成,该模型应显示出约 99.6%的最终测试(即评估)准确性,这优于我们在第 4.2 节中结果的 99.0%。那么,这种基于 node 的模型与基于浏览器的模型之间的区别是什么,为什么导致准确性的提高?如果您使用数据训练数据在 tfjs-node 和浏览器版本 TensorFlow.js 中训练相同的模型,则应该获得相同的结果(效果或随机权重初始化除外)。要回答此问题,让我们看一下基于 node 的模型的定义。该模型在文件 model.js 中构建,该文件由 main.js 导入。
# 代码 4.5 在 Node.js 中为 MNIST 定义更大的 convnet
const model = tf.sequential();
model.add(
tf.layers.conv2d({
inputShape: [28, 28, 1],
filters: 32,
kernelSize: 3,
activation: 'relu'
})
);
model.add(
tf.layers.conv2d({
filters: 32,
kernelSize: 3,
activation: 'relu'
})
);
model.add(tf.layers.maxPooling2d({ poolSize: [2, 2] }));
model.add(
tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu'
})
);
model.add(
tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu'
})
);
model.add(tf.layers.maxPooling2d({ poolSize: [2, 2] }));
model.add(tf.layers.flatten());
model.add(tf.layers.dropout({ rate: 0.25 }));
model.add(tf.layers.dense({ units: 512, activation: 'relu' }));
model.add(tf.layers.dropout({ rate: 0.5 }));
model.add(tf.layers.dense({ units: 10, activation: 'softmax' }));
model.summary();
model.compile({
optimizer: 'rmsprop',
loss: 'categoricalCrossentropy',
metrics: ['accuracy']
});
该模型的摘要如下:
_________________________________________________________________
Layer (type) Output shape Param #
=================================================================
conv2d_Conv2D1 (Conv2D) [null,26,26,32] 320
_________________________________________________________________
conv2d_Conv2D2 (Conv2D) [null,24,24,32] 9248
_________________________________________________________________
max_pooling2d_MaxPooling2D1 [null,12,12,32] 0
_________________________________________________________________
conv2d_Conv2D3 (Conv2D) [null,10,10,64] 18496
_________________________________________________________________
conv2d_Conv2D4 (Conv2D) [null,8,8,64] 36928
_________________________________________________________________
max_pooling2d_MaxPooling2D2 [null,4,4,64] 0
_________________________________________________________________
flatten_Flatten1 (Flatten) [null,1024] 0
_________________________________________________________________
dropout_Dropout1 (Dropout) [null,1024] 0
_________________________________________________________________
dense_Dense1 (Dense) [null,512] 524800
_________________________________________________________________
dropout_Dropout2 (Dropout) [null,512] 0
_________________________________________________________________
dense_Dense2 (Dense) [null,10] 5130
=================================================================
Total params: 594922
Trainable params: 594922
Non-trainable params: 0
_________________________________________________________________
我们的 tfjs-node 模型和基于浏览器的模型之间的主要区别是:
- 基于 node 的模型具有四个 conv2d 层,比基于浏览器的模型多一层
- 与基于浏览器的模型(100)中的对应层相比,基于 node 的模型中的隐藏密集层具有更多的单元(512)。
- 总体而言,基于 node 的模型的权重参数约为基于浏览器的模型的 18 倍
- 基于 node 的模型在扁平层和稠密层之间插入了两个 dropout 层
上面列出的差异 1-3 使基于 node 的模型比基于浏览器的模型具有更高的容量。它们也使基于 node 的模型过于占用内存和计算量,无法在浏览器中进行训练。正如我们在第 3 章了解到的那样,更大的模型容量会带来更大的过度拟合风险。差异 4(即包含 dropout 层)可以缓解过度拟合的风险。
# 利用 dropout 层减少过度拟合
Dropout 层是您在本章中遇到的另一个新的 TensorFlow.js 图层类型。这是减少深度神经网络过度拟合的最有效且广泛使用的方法之一。其功能可以简单描述:
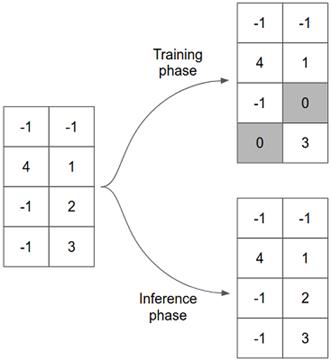
- 在训练阶段(即 Model.fit()调用期间),它将输入张量中元素的一部分随机设置为零(即“丢弃”),结果便是输出张量。就本示例而言,丢弃层仅具有一个配置参数:丢弃率(例如,代码清单 4.5 中所示的两个 rate 字段)。例如,假设将丢弃层配置为具有 0.25 的丢弃率,输入张量是值为[0.7,-0.3、0.8,-0.4]的一维张量,则输出张量可以为[0.7,-0.3、0.0 ,例如 0.4],即随机选择了输入张量的 25%并将其设置为值 0。在反向传播期间,此随机置零会类似地影响丢弃层上的梯度张量。
- 在推理期间(即 Model.predict()和 Model.evaluate 调用),丢弃层不会随机在张量输入元素进行至零。取而代之的,输入只是为输出进行传递而没有更改(即映射)。
下面的图 4.11 展示了一个带有 2D 输入张量的丢弃层在训练和测试时是如何工作的。
# 图 4.11 丢弃层的工作方式示意图。在此示例中,输入张量为 2D,形状为[4,2]。丢弃层的 rate 配置为 0.25,这导致在训练阶段随机选择输入张量的 25%(即八分之二)并将其设置为零。在推断阶段,该层充当普通的直通层。
如此简单的算法是解决过度拟合的最有效方法之一,这似乎很奇怪。为什么行得通?丢弃算法(神经网络算法中的一种)的发明者 Geoff Hinton 说,他受到一些银行用来防止员工欺诈机制的启发。用他自己的话说:
“我去了银行。出纳员不断变化,我问其中一个为什么。他说他不知道,但是他们四处走动。我认为这一定是因为需要员工之间的合作才能成功欺骗银行。这使我意识到,在每个示例中随机删除神经元的不同子集将防止串谋,从而减少过度拟合。”
为了将其纳入深度学习的术语中,在层的输出值中引入噪声会破坏偶然性模式,这种偶然性模式对于数据的真实模式而言并不重要(Hinton 称为“阴谋”)。在本章结尾的练习 3 中,您应该尝试从 model.js 中基于 node 的 convnet 中删除两个丢弃层,再次训练模型,并查看其训练,验证和评估精度如何发生变化。
下面的代码清单 4.6 显示了我们用来训练和评估增强型 convnet 的关键代码。如果将此处的代码与清单 4.2 中的代码进行比较,则可以理解两个代码块之间的相似性。两者均以 Model.fit()和 Model.evaluate()调用为中心。语法和样式相同,不同之处在于如何在不同的用户界面(即终端与浏览器)上呈现或显示损耗值,准确性值和训练进度。
这显示了 TensorFlow.js 的重要功能,TensorFlow.js 是一个跨越前端和后端的 JavaScript 深度学习框架: 就模型的创建和训练而言,无论您是使用 Web 浏览器还是使用 Node.js,在 TensorFlow.js 中编写的代码都是相同的。
# 代码 4.6 在 tfjs-node 中训练和评估增强 convnet
await model.fit(trainImages, trainLabels, {
epochs,
batchSize,
validationSplit
});
const { images: testImages, labels: testLabels } = data.getTestData();
const evalOutput = model.evaluate(testImages, testLabels);
console.log('\nEvaluation result:');
console.log(
` Loss = ${evalOutput[0].dataSync()[0].toFixed(3)}; ` + `Accuracy = ${evalOutput[1].dataSync()[0].toFixed(3)}`
);
# 4.3.3 从 Node.js 保存模型并在浏览器中加载模型
训练模型会消耗 CPU 和 GPU 资源,并且需要一些时间。您不想丢掉训练的果实。如果不保存模型,则下次运行 main.js 时必须从头开始。本节显示了训练后如何保存模型以及如何将保存的模型导出为磁盘上的文件(称为“检查点”或“工件”)。我们还将展示如何在浏览器中导入检查点,将其重构为模型并将其用于推理。
main.js 中 main()函数的最后一部分由节省模型的代码组成:
# 代码 4.7 将训练好的模型保存到 tfjs-node 的文件系统中。
if (modelSavePath != null) {
await model.save(`file://${modelSavePath}`);
console.log(`Saved model to path: ${modelSavePath}`);
}
文件系统上的目录。该方法采用单个参数,该参数是以方案 file:// 开头的 URL 字符串。注意,因为我们使用的是 tfjs-node,所以可以将模型保存在文件系统上。TensorFlow.js 的浏览器版本还提供了 model.save()API,但无法直接访问机器的本机文件系统,因为出于安全原因,浏览器禁止这样做。如果我们在浏览器中使用 TensorFlow.js,则必须使用非文件系统保存目标(例如浏览器的本地存储和 IndexedDB)。这些对应于 file:// 以外的 URL 方案。
model.save()是一个异步函数,因为它通常涉及文件或网络 IO。因此,我们在 save()调用中使用了 await。假设 modelSavePath 的值为/ tmp / tfjs-node-mnist,在 model.save()调用完成之后,您可以检查目录的内容:
ls - lh / tmp / tfjs - node - mnist;
可能会打印如下文件列表:
-rw-r--r-- 1 user group 4.6K Aug 14 10:38 model.json
-rw-r--r-- 1 user group 2.3M Aug 14 10:38 weights.bin
在那里,您可以看到两个文件:
- model.json 是一个 JSON 文件,其中包含已保存的模型拓扑。这里所谓的“拓扑”包括组成模型的层的类型,它们各自的配置参数(例如,用于 conv2d 层的过滤器和用于丢弃层的速率),以及各层连接彼此的方式。对于 MNIST 卷积网络而言,连接很简单,因为它是一个顺序模型。连接模式较少的模型,也可以使用 model.save()将其保存到磁盘。 除了模型拓扑外,model.json 还包含模型权重的清单。该部分列出了模型所有权重的名称,形状和数据类型,以及存储权重值的位置。这将我们带到第二个文件:weights.bin。
- 顾名思义,weights.bin 是一个二进制文件,用于存储模型的所有权重值。它是平坦的二进制流,没有划分各个权重的开始和结束位置。该“元信息”在 model.json 中的 JSON 对象的权重清单部分中可用。
要使用 tfjs-node 加载模型,可以使用 tf.loadLayersModel()方法,指向 model.json 文件的位置(示例代码中未显示)
const loadedModel = await tf.loadLayersModel('file:///tmp/tfjs-node-mnist');
tf.loadLayersModel()通过反序列化 model.json 中保存的拓扑数据来重构模型。然后,tf.loadLayersModel()使用 model.json 中的清单读取 weights.bin 中的二进制权重值,并将模型的权重强制设置为这些值。
像 model.save()一样,tf.loadLayersModel()是异步的,因此我们在此处调用 await。一旦调用返回,从所有意图和目的来看,loadedModel 对象等效于使用清单 4.5 和 4.6 中的 JavaScript 代码创建和训练的模型。您可以通过调用其 summary()方法来打印该模型的效果,通过调用其 predict()方法来使用其执行推理,通过使用 validate()方法来评估其准确性,甚至可以使用 fit()方法对其进行重新训练。如果需要,还可以再次保存模型。当我们在第 5 章中讨论转移学习时,重新训练和保存已加载模型的工作流程将很重要。
上一段中所说的内容也适用于浏览器环境。您保存的文件可用于重构网页中的模型。重构后的模型支持完整的 tf.LayersModel 工作流程,但需要注意的是,如果您重新训练整个模型,由于增强的卷积网络很大,因此它将特别缓慢且效率低下。在 tfjs-node 和浏览器中加载模型之间唯一的根本不同是,在浏览器中应使用 file://以外的 URL 方案。通常,您可以将 model.json 和 weights.bin 文件作为静态资产文件放置在 HTTP 服务器上。假设您的主机名是 localhost,并且文件在服务器路径 my / models /下显示;您可以使用以下行在浏览器中加载模型:
const loadedModel = await tf.loadLayersModel('http:///localhost/my/models/model.json');
在浏览器中处理基于 HTTP 的模型加载时,tf.loadLayersModel()在后台调用浏览器的内置访存函数。因此,它具有以下功能和特性:
- 同时支持 http:#和 https:#。
- 支持相对服务器路径。实际上,如果使用相对路径,则可以省略 URL 的 http://或 https://部分。例如,如果您的网页位于服务器路径 my / index.html 上,而模型的 JSON 文件位于 my / models / model.json 上,则可以使用相对路径 model / model.json,即
const loadedModel = await tf.loadLayersModel('models/model.json');
- 要为 HTTP / HTTPS 请求指定其他选项,应使用 tf.io.browserHTTPRequest()方法代替字符串参数。例如,要在模型加载期间包括凭证和标头,可以执行以下操作:
const loadedModel = await tf.loadLayersModel(
tf.io.browserHTTPRequest('http://foo.bar/path/to/model.json', {
credentials: 'include',
headers: { key_1: 'value_1' }
})
);