与我交流

# 6.5 处理数据中的问题
原始数据几乎都无法确保没有问题。如果你正在使用自己的数据源,而且你没有和专家一起梳理特征、分布和相关性,那么很有可能存在会削弱或破坏你的机器学习模型的缺陷。作为作者,可以自信地说,这是因为我们在许多领域指导机器学习系统的构建和我们自己构建一些系统得到的经验。最常见的问题是一些模型没有收敛,或者收敛到远低于预期的精度。更难以调试的模式是,当模型收敛并在验证和测试数据上表现良好,但在生产中却未能达到预期。这个原因有时会是建模问题,或是超参数问题,或者只是运气不好,但是,到目前为止,这些错误最常见的根本原因是数据中存在缺陷。
我们使用的所有数据集(如MNIST、iris flowers、speech commands)都经过了手动检查、错误示例的删减、格式化为标准和合适的格式,以及其他我们没有提到的数据科学操作。数据问题可以以多种形式出现,包括缺少字段、相关样本和分布不均。在处理数据方面上,人们可以写一本书。请参阅Ashley Davis的“"Data Wrangling with Javascript”以获得更全面的阐述!
数据科学家已经成为许多公司的全职专业人员。这些专业人员使用的工具和遵循的最佳实践是多种多样的,通常取决于所审查的特定领域,但在本节中,我们将介绍一些基本知识,并指出一些工具,以帮助您避免长时间模型调试结果发现是数据本身存在缺陷。为了更深入地研究数据科学,我们将为您提供更多的参考资料。
# 6.5.1数据理论
为了检测和修复脏数据,首先必须知道好数据是什么样子的。
支持机器学习领域的许多理论都建立在我们的数据来自概率分布的前提之上。在这个公式中,我们的训练数据由一组独立的样本组成。每个样本被描述为(X,y)对,其中y是我们希望从X部分预测的样本部分。推断数据由一组样本组成,样本的分布与训练数据完全相同。训练数据和推理数据之间唯一重要的区别是,在推理时我们看不到y。我们应该使用从训练数据中学习到的统计关系,从X部分估计样本的y部分。
现实生活中的数据基本无法达到柏拉图的理想状态。例如,我们的训练数据和推理数据是来自不同分布的样本,比如存在数据集偏差。举个简单的例子,如果你根据天气和时间等特征来估计道路交通量,并且你的所有训练数据都来自周一和周二,而你的测试数据来自周六和周日,那么预期模型的精度将低于最佳值。平日的汽车交通量分布与周末的交通量分布不尽相同。另一个例子是,假设我们正在构建一个人脸识别系统,基于从我们祖国收集的标记数据来训练该系统来识别人脸。但是会发现,该系统在不同人口分布的地区使用时会遇到困难和失败。在实际的机器学习设置中,您将遇到的大多数数据偏差问题将比这两个示例更加微妙。
另一种使得数据集偏差的方式是,在数据收集期间发生了一些变化。例如,我们正在采集音频样本来学习语音信号,但中间我们的麦克风坏了,因此我们购买了升级版,训练集的下半部分将有不同于上半部分的噪声和音频分布。我们使用新的麦克风进行测试,因此训练和测试集之间也存在偏差。
在某种程度上,数据集偏差是不可避免的。对于许多应用程序,我们的训练数据必然来自过去,而我们传递给应用程序的数据必然来自现在。产生的样本必然会随着文化、兴趣、时尚和其他混杂因素的变化而变化。在这样的情况下,我们所能做的就是了解偏差并将影响降到最低。出于这个原因,许多生产环境中的机器学习模型经常使用最新的可用训练数据进行重新训练,试图跟上不断变化的分布。
数据样本无法达到理想的另一问题是无法独立。理想状态是样本是独立的、同分布的(IID)。但在一些数据集中,一个样本与下一个样本相互联系。这些数据集的样本不是独立的。数据库系统经常为我们组织数据,甚至不需要我们去操作。因此,当您从某个源获取数据时,必须非常小心,以确保结果为无序的模式。比如,我们希望对加利福尼亚州的住房成本进行估算,以便申请房地产。我们得到了全国各地房价的CSV数据集,以及相关特征,如房间数量、开发年限等。我们可能会很快开始从特征到价格的简单训练,因为我们有数据并且知道如何去做。但我们知道数据往往有缺陷,所以决定先看看。我们首先使用 tf.data.Datasets和Plotly.js在数组中绘制一些特性与它们的索引。
# 清单6.20 使用tfjs数据构建特性与索引图:摘自https://codepen.io/tfjs-book/pen/MLQOem
const plottingData = {
x: [],
y: [],
mode: 'markers',
type: 'scatter',
marker: {symbol: 'circle', size: 8}
};
const filename = 'https://storage.googleapis.com/learnjs-data/csv-datasets/california_housing_train.csv';
const dataset = tf.data.csv(filename);
await dataset.take(1000).forEachAsync(row => {
plottingData.x.push(i++);
plottingData.y.push(row['longitude']);
});
Plotly.newPlot('plot', [plottingData], {
width: 700,
title: 'Longitude feature vs sample index',
xaxis: {title: 'sample index'},
yaxis: {title: 'longitude'}
});
# 图6.3 四个数据集特征与样本索引的关系图。理想情况下,在一个干净的IID数据集中,我们希望样本索引不会提供任何关于特征值的信息。我们看到,对于某些特征,y值的分布显然依赖于x。糟糕的是,“longitude”特征似乎是按样本索引排序的。
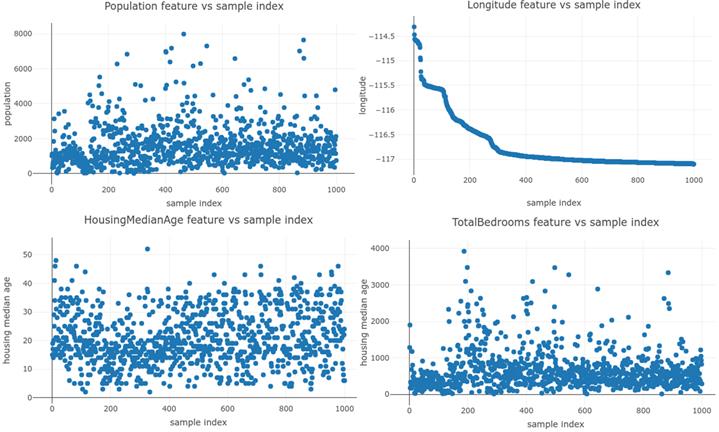
假设我们要用这个数据集分割训练和测试数据,在这里我们采集前500个样本进行训练,其余的样本进行测试。会发生什么?看上去,我们将利用一个地理区域的数据进行训练,并利用另一个地理区域进行测试。图6.3中的第二个图显示了问题所在:第一个样本的经度比其他任何样本都高。特征中可能还有很多信号,模型会“工作”一些,但不会像我们的数据是真正的IID那样精确或高质量。如果进一步调试,我们可能会花上几天或几周时间玩不同的模型和超参数,然后我们才会去看看我们的数据!
我们能做些什么来对数据进行下清理呢?解决这个问题非常简单。为了消除数据和索引之间的关系,我们可以将数据按随机顺序洗牌。然而,必须注意,Tensorflow.js数据集有一个内置的shuffle程序。这意味着样本在一个固定大小的窗口内被随机地洗牌,但不会做其他工作了。因为TensorFlow.js数据集可以获取无限数量的样本。为了彻底洗牌一个永无止境的数据源,你首先需要等到它完成…
for (let windowSize of [10, 50, 250, 6000]) {
shuffledDataset = dataset.shuffle(windowSize);
myPlot(shuffledDataset, windowSize)
}
那么,我们可以用这个流式窗口shuffle来处理我们的经度特性吗?当然,如果我们知道数据集的大小(在本例中是17000),我们可以将窗口设置为大于整个数据集。在窗口大小的限制下,窗口洗牌和我们通常的穷举洗牌是相同的。如果我们不知道我们的数据集有多大,或者数据集太大(即,我们不能在内存缓存中同时保存整个数据集),我们可能不得不使用更少的数据。
# 图6.4 是用https://codepen.io/tfjs-book/pen/JxpMrj创建的,它演示了当我们使用4种不同的窗口大小对数据进行tf.data.Dataset的shuffle时会发生什么
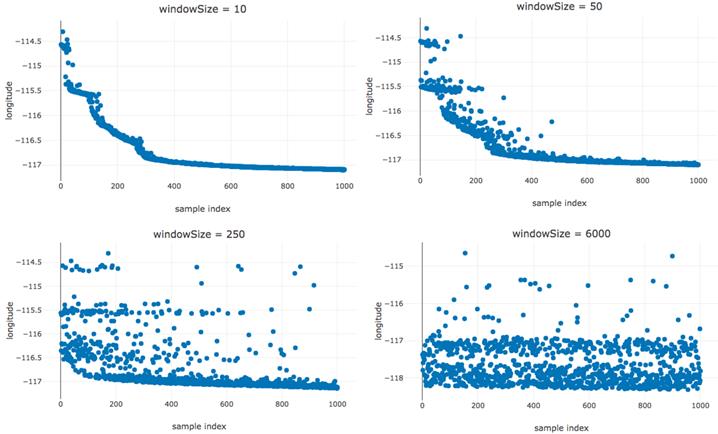
直到窗口大小达到6000,肉眼才能看到数据可以被视为IID。那么6000是合适的窗户尺寸吗?有没有一个介于250到6000之间的数字会起作用?这里正确的方法是使windowSize>=数据集中的样本数来洗牌整个数据集。对于内存限制、时间限制或可能不受限制的数据集,这是不可能的,您必须进一步检查分布以确定适当的窗口大小。
图6.4四个无序数据集的四个经度与样本索引图。洗牌窗口大小各不相同,从10个增加到6000个样本。我们看到,即使窗口大小为250,索引和特征值之间仍然有很强的关系。在开头附近有更多的大值。直到我们使用的shuffle窗口大小几乎和数据集一样大。
# 6.5.2 数据检测和清洗问题
在上一节中,我们介绍了如何检测和修复一种类型的数据问题:样本的依赖性。当然,这只是数据中可能出现的多种问题之一。不过,让我们来看看这里的一些问题,您将认识到它们,并知道要搜索哪些术语来查找更多信息。
- 异常值 例如,我们使用的是健康统计数据集,典型的成年人体重大约在40到130公斤之间。在我们的数据集中,99.9%的样本都在这个范围内,但我们经常遇到145000公斤或0公斤或更糟的非理性样本报告NaN,我们会将这些样本视为异常值。对于如何正确处理异常值,有很多意见。理想情况下,我们的训练数据中很少有异常值,而且我们知道如何找到它们。如果我们可以编写一个程序从数据集中删除它们,然后在没有它们的情况下继续训练。当然,我们也希望在推理时触发相同的逻辑,否则我们将引入偏差。
在特征级别处理异常值的另一种常见方法是通过提供合理的最小值和最大值来提供阈值。在我们的例子中,我们可以用以下内容:
weight = Math.min(MAX_WEIGHT, Math.max(weight, MIN_WEIGHT));
在这种情况下,最好添加一个新特性,表明异常值已被替换。这样,可以将原始值40kg与-5kg区分开来,从而使网络有机会了解异常值状态与目标之间的关系。
isOutlierWeight = weight > MAX_WEIGHT | weight < MIN_WEIGHT;
- 丢失的数据 我们经常会遇到一些样本缺少某些特征的情况。这可能有很多原因。有时数据来自手工输入的表单,有些字段被跳过。有时传感器在数据收集时会出现故障。对于一些示例,可能有些特征就是没有意义。例如,一套从未售出的房子最近的售价是多少?或者没有电话的人的电话号码是多少?
与异常值一样,有很多方法可以解决数据丢失的问题,而数据科学家对于哪些技术适合于哪些情况有不同的看法。哪种技术最好取决于一些因素,包括特征丢失的可能性是否取决于特征本身,或者是否可以从样本中的其他特征预测“丢失”。
当数据从我们的训练集中丢失时,我们必须应用一些修正来将数据转换成一个固定形状的张量。有四种处理丢失数据的重要技术。
最简单的方法是,如果训练数据充足,而缺少的字段很少,则丢弃缺少数据的训练样本。但是,请注意,这可能会在您的训练模型中引入偏差。想象这样一个问题:正类比负类更常丢失数据。只有当丢失的数据是MCAR(随机丢失)时,才能完全安全地丢弃样本。
# 清单6.21 通过删除数据来处理丢失的特征
const filteredDataset = tf.data.csv(csvFilename).filter(e => e['featureName']);
处理缺失数据的另一种技术是用一些值填充缺失数据,也称为插补。常见的插补技术包括用缺失的数字特征值替换该特征的均值、中值。丢失的分类特征可能会替换为该特征的最常见值(也是模式)。更复杂的技术包括从可用的特性中为缺失的特性构建预测器并使用它们。事实上,使用神经网络是填补缺失数据的“复杂技术”之一。使用插补法的缺点是学习者没有意识到特征缺失。如果缺失中有关于目标变量的信息,将在插补中丢失。
# 清单6.22 用归责法处理缺失特征
async function calculateMeanOfNonMissing(dataset, featureName) {
let samplesSoFar = 0;
let sumSoFar = 0;
await dataset.forEachAsync(row => {
const x = row[featureName];
if (x != null) {
samplesSoFar += 1;
sumSoFar += x;
}
});
return sumSoFar / samplesSoFar;
}
function replaceMissingWithImputed(row, featureName, imputedValue)) {
const x = row[featureName];
if (x == null) {
return {...row, [featureName]: imputedValue};
} else {
return row;
}
}
const rawDataset = tf.data.csv(csvFilename);
const imputedValue = await calculateMeanOfNonMissing(rawDataset, 'myFeature');
const imputedDataset = rawDataset.map(row => replaceMissingWithImputed(row, 'myFeature', imputedValue);
有时丢失的值会替换为sentinel值。例如,丢失的体重值可能会被替换为-1,表示没有体重。如果您的数据出现这种情况,请在将哨兵发现为异常值之前小心处理它(例如,根据我们前面的示例,将-1替换为40kg)。
如果特征的“丢失”与要预测的目标之间存在关系,则模型可以使用哨兵值。在实践中,该模型将花费一些计算资源来学习如何区分特征何时用作值,何时用作指标。
也许管理缺失数据的最可靠方法是既使用插补来填充值,又添加第二个指标特征,以便在该特征缺失时与模型通信。在这种情况下,我们将用猜测替换丢失的体重,还添加了一个新特征“体重丢失”,即体重丢失时为1,提供体重时为0。这允许模型利用缺失(如果有价值的话),并且不将其与权重的实际值合并。
# 清单6.23 添加用于指示丢失的功能
function addMissingness(row, featureName)) {
const x = row[featureName];
const isMissing = (x == null) ? 1 : 0;
return {...row, [featureName + '_isMissing']: isMissing};
}
const rawDataset tf.data.csv(csvFilename);
const datasetWithIndicator = rawDataset.map((row) => addMissingness(row, featureName);
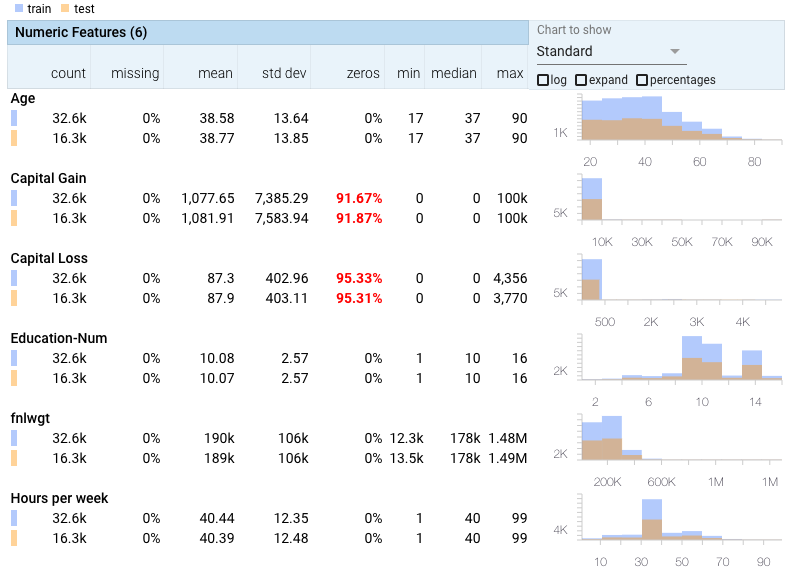
- 偏差 在本章的前面,我们描述了偏差的概念,即从一个数据集到另一个数据集的分布差异。这是机器学习实践者在将经过训练的模型部署到生产中时面临的主要问题之一。检测偏差涉及对数据集的分布进行建模,并对它们进行比较,看它们是否匹配。快速查看数据集统计信息的一个简单方法是使用Facets之类的工具。截图见图6.5。Facets将分析和总结您的数据集,以允许您查看每个特性分布,这将帮助您快速解决数据集之间不同分布的问题。
一个简单的基本偏差检测算法可以计算每个特征的平均值、中值和方差,并检查数据集之间的差异是否在可接受的范围内。更复杂的方法可能试图预测给定的样本,它来自哪个数据集。理想情况下,这是不可能的,因为它们来自同一个分布。如果可以预测一个数据点是来自训练还是测试,这是一个偏差的迹象。
# 图6.5 Facets的屏幕截图,显示了UC-Irvine人口普查数据集的训练和测试的每个特征值分布。此数据集是https://pair-code.github.io/facets/ 默认数据集,但您可以导航到该站点并上载自己的csv进行比较。
脏字符串 通常,分类数据是作为字符串值特性提供的。例如,当用户访问您的网页时,您可以将浏览器的日志与“FIREFOX”、“SAFARI”和“CHROME”等值一起使用。通常,在将这些值放到深度学习模型中之前,会将这些值转换为整数(通过已知词汇表或哈希),然后将其映射到n维向量空间(请参见第9.2.3节中的“单词嵌入”)。一个常见的问题是,一个数据集中的字符串与另一个数据集中的字符串具有不同的格式。例如,训练数据可能包含“FIREFOX”,而在测试时,模型接收包含换行符的“FIREFOX\n”,或包含引号的“FIREFOX”。
在你的数据中要注意的其他事情 过度不平衡的数据——如果有一些特性对数据集中的几乎每个样本都取相同的值,那么可以考虑去掉它们。这种信号很容易过拟合,而深度学习方法不能很好地处理非常稀疏的数据。
数值/分类区别——有些数据集将使用整数来表示枚举集的元素,当这些整数的秩顺序没有意义时,这可能会导致问题。例如,如果我们有一组枚举的音乐类型,如摇滚、古典等,并且有一个将这些值映射到整数的词汇表,那么当我们将枚举值传递到模型中时,处理这些值(如枚举值)是很重要的。这意味着使用一个hot或embedding对值进行编码(参见第9章)。否则,这些数字将被解释为浮点值,这表明基于编码之间的数字距离的术语之间存在虚假关系。
数据值差异——这在前面已经提到过,但在这一节中需要重复一下数据可能出现的问题。注意具有较大比例差异的数字特征。它们会导致训练不稳定。一般来说,最好在训练前对数据进行z-标准化(标准化平均值和标准差)。只需确保在测试期间使用与训练期间相同的预处理。您可以在第2章中iris示例中看到这方面的示例。
偏见、安全性、隐私——如果您正在开发ML解决方案,那么您必须花时间至少熟悉管理偏见、安全性和隐私的最佳实践的基本知识。即使是偏差安全或隐私方面的小故障也可能导致令人尴尬的系统故障,从而迅速导致客户寻找其他更可靠的解决方案。
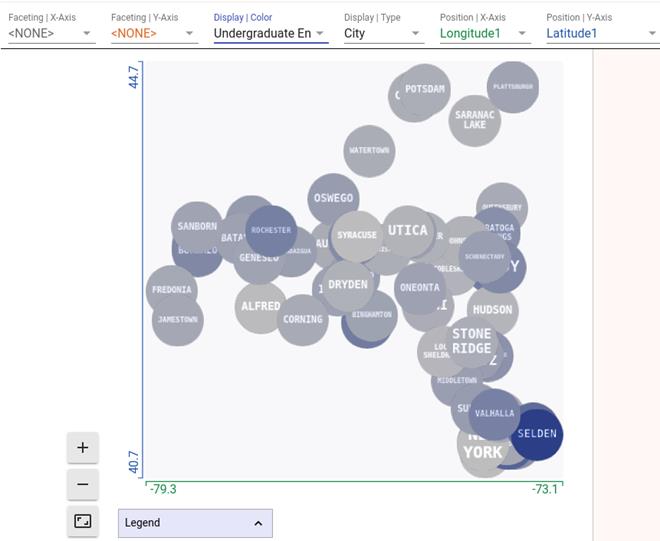
一般来说,你应该花时间让你的数据处理成期望的那样。有很多工具可以帮助您做到这一点,比如使用Observable、Jupyter、Kaggle Kernel或Colab等,到Facets等图形用户界面工具。在这里,我们使用Facets的绘图功能称为“Facets Dive”来查看“纽约州立大学”数据集中的观点。Facets dive允许用户从数据中选择列,并以自定义方式直观地表示每个字段。在这里,我们使用下拉菜单使用“Longitude1”字段作为点的x位置,“Latitude1”字段作为点的y位置,“City”字符串字段作为点的名称,“本科招生”作为点的颜色。我们期望在二维平面上绘制的经度和纬度能显示出纽约州的地图,事实上,这就是我们所看到的。地图的正确性可以通过与SUNY的网页www.SUNY.edu/attentie/访问us/campus/map/进行比较来验证。
# 图6.6 另一个Facets的屏幕截图,这次从上面的数据csv示例探索“纽约州校园”数据集。这里我们看到“Facets Dive”视图,它允许您探索数据集不同特性之间的关系。显示的每个点都是数据集中的一个数据点,这里我们对其进行了配置,点的x位置设置为“Latitude1”特征,y位置设置为“Longitude1”特征,颜色与“本科招生”特征相关,上面的单词设置为“城市”特征,从这幅图像中我们可以看到纽约州的大致轮廓,西部是布法罗,东南部是纽约。很显然,塞尔登市是大学招生规模最大的校园之一。