与我交流

# 6.4 访问数据的常见模式
所有开发人员都需要一些解决方案来将他们的数据连接到他们的模型。这些数据包括普通数据集或众所周知的实验数据集(如MNIST),或企业内完全自定义的专有数据格式。在本节中,我们将回顾tf.data如何帮助简化和维护这些连接。
# 6.4.1使用CSV格式数据
除了使用普通数据集之外,访问数据的最常用方法还包括加载以某种文件格式存储好的数据。数据文件通常以CSV(逗号分隔值)格式存储[101],因为它的简单性、可读性和广泛的支持。其他格式在存储效率和访问速度方面也有其他优势,但CSV可能被视为数据集的通用语言。在JS社区中,我们通常希望能够方便地从某个HTTP端点流式传输数据。这就是为什么TensorFlow.js为CSV文件中的数据流和操作提供原生支持的原因。
在第6.2.2节中,我们简要描述了如何构建一个由CSV文件支持的tf.data.Dataset。在本节中,我们将深入讨论CSV API,以展示tf.data如何更便捷的使用这些数据源。我们将描述一个示例应用程序,它连接到远程CSV数据集,计算数据集的元素,并为用户提供选择和打印单个示例的功能。使用现在熟悉的命令查看示例:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/data-csv
yarn && yarn watch
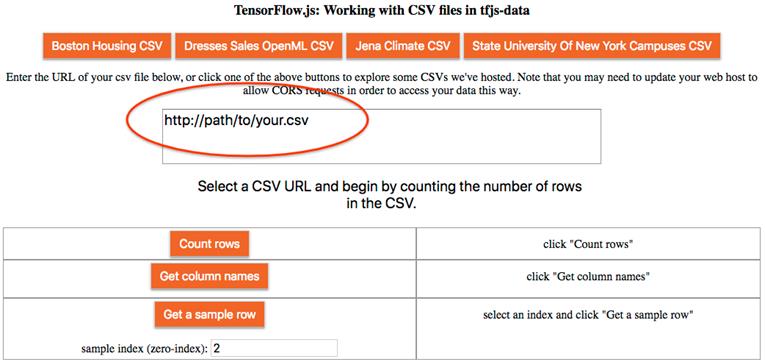
这将弹出一个网站,指示我们输入托管CSV文件的URL,或使用建议的URL之一,例如“Boston Housing CSV”。在URL输入框下面,提供了执行操作的三个按钮。1) 计算数据集中的行数,2)检索CSV的列名(如果存在),3)访问和打印数据集中的指定示例行。让我们来看看它们是如何工作的,以及tf数据API如何使它们变得非常简单。
# 图6.2 tfjs数据CSV示例的Web UI。单击顶部的一个预先设置的CSV文件的按钮,或者输入CSV的路径。如果使用路径文件,请确保为CSV启用CORS访问。
使用如下命令从远程CSV创建tfjs数据集非常简单:
const myData = tf.data.csv(url);
url使用http://、https://、file://协议,或者是RequestInfo。此调用实际上不会向URL发出任何请求,以检查文件是否存在或是否可访问。在下面的清单6.10中,首先在异步调用myData.forEach()获取CSV。foreach调用的函数将简单地对数据集中的元素进行字符串化和打印,但我们运用此方法执行其他操作,例如为集合中的每个元素生成UI元素或计算报表的信息。
# 清单6.10在远程CSV文件中打印前10条记录
const url = document.getElementById('queryURL').value;
const myData = tf.data.csv(url);
await myData.take(10).forEach(x => console.log(JSON.stringify(x))));
CSV数据集通常使用第一行作为包含与每列关联的名称的说明。默认情况下,tf.data.csv()可以使用作为第二个参数传入的csvConfig对象来控制第一行说明。如果列名称不是由CSV文件本身提供的,则可以在构造函数中手动提供,如下所示:
const myData = tf.data.csv(url, {
hasHeader: false,
columnNames: ["firstName", "lastName", "id"]
});
如果为CSV数据集手动提供列名配置,则它将优先于从数据文件中读取标题行。默认情况下,数据集将假定第一行是标题行。如果第一行不是标题,则必须手动配置。 一旦对象CSVDataset存在,就可以使用dataset.columnNames()查询获取列名,其将返回列名的有序字符串列表。columnNames()是专属CSVDataset的,通常不能从从其他源构建的数据集中获得。示例中的“Get column names”按钮实现此API。请求列名会对所提供的URL进行一个fetch调用,以访问和解析第一行,清单6.11为异步调用。
# 清单6.11从CSV访问列名:从tfjs-examples/CSV data/index.js
const url = document.getElementById('queryURL').value;
const myData = tf.data.csv(url);
const columnNames = await myData.columnNames();
console.log(columnNames);
// Outputs something like ["crim", "zn", "indus", ..., "tax", "ptratio", "lstat"] for Boston Housing.
在清单6.12中,我们展示了web应用程序如何打印CSV文件的一个选定行。为了满足这个请求,我们将首先使用该Dataset.skip()方法创建一个与原始数据集相同的新数据集,跳过n-1元素。然后,使用 Dataset.take()创建一个以此元素结束的数据集。最后,我们将使用Dataset.toArray() 将数据提取到标准JavaScript数组中。如果一切顺利,我们的请求将生成一个数组,其中正好包含指定位置的元素。
# 清单6.12从远程CSV访问选定行:从tfjs-examples/CSV data/index.js
const url = document.getElementById('queryURL').value;
const sampleIndex = document.getElementById('whichSampleInput').valueAsNumber;
const myData = tf.data.csv(url);
const sample = await myData
.skip(sampleIndex)
.take(1)
.toArray();
console.log(sample);
// Outputs something like: [{crim: 0.3237, zn: 0, indus: 2.18, ..., tax: 222, ptratio: 18.7, lstat: 2.94}]
#For Boston Housing.
现在我们获取到行的输出,从清单6.12中的console.log的输出中得到,它以对象的形式将列名映射到值,并将其规范化插入到文档中。需要注意的是:如果我们获取一个不存在的行,比如获取只有300元素数据集的第400个元素,那么我们最终将得到一个空数组。 当连接到远程数据集时,使用错误的URL是很常见的。在这种情况下,最好捕获错误并向用户提供合理的错误消息。由于dataset在获取数据之前不会与远程资源关联,因此必须注意在正确的位置编写错误处理。代码清单6.13显示了在我们的CSV示例web app中如何处理错误的一小段代码。
# 清单6.13处理因连接失败而产生的错误:从tfjs-examples/csv data/index.js
const url = 'http://some.bad.url';
const sampleIndex = document.getElementById('whichSampleInput').valueAsNumber;
const myData = tf.data.csv(url);
let columnNames;
try {
columnNames = await myData.columnNames();
} catch (e) {
ui.updateColumnNamesMessage(`Could not connect to ${url}`);
}
在第6.3节中,我们学习了如何使用 model.fitDataset()。该方法需要一个特定形式的数据集。其需要两个属性的对象{xs, ys},其中xs是表示输入的张量,ys表示关联目标的张量。默认情况下,CSV数据集将以JS对象的形式返回,我们也可以配置数据集使其更接近训练所需的元素。我们需要使用tf.data.csv()的csvConfig.columnConfigs字段。比如一个CSV文件,它有三列,“俱乐部”、“实力”、“距离”。如果我们希望预测俱乐部的物理距离以及实力,可以在原始输出上应用一个map函数,将字段排列成xs和ys,或者,我们可以配置CSV来完成这项工作。表6.4显示了如何配置CSV数据集以分离特征和标签属性并执行批处理,以便输出适合model.fitDataset() 的输入。
# 表6.4配置CSV数据集使用model.fitDataset
| 数据集创建 | 代码 | dataset.take(1).toArray()[0]结论 |
|---|---|---|
| 默认csv | dataset = tf.data.csv(csvURL) | {club: 1, strength: 45, |
| distance: 200} | ||
| 使用columnConfigs参数 | columnConfigs = {distance: {isLabel: true}};dataset = tf.data.csv(csvURL, {columnConfigs}); | {xs: {club: 1, strength: 45}, ys: {distance: 200}} |
| 使用columnConfigs参数后分批 | columnConfigs = {distance: {isLabel: true}};dataset = tf.data.csv(csvURL, {columnConfigs}).batch(128); | [xs: {club: Tensor, strength: Tensor},ys: {distance:Tensor}](每一个张量形状 [128]) |
| 使用columnConfigs参数后分批并将对象转化成数组 | columnConfigs = {distance: {isLabel: true}};dataset = tf.data.csv(csvURL, {columnConfigs}).map(({xs, ys}) =>{return {xs:Object.values(xs), ys:Object.values(ys)}; }).batch(128); | {xs: Tensor, ys: Tensor};其中{xs: [number, number], ys: [number]}的格式 |
# 信息6.1
上述例子通过远程url得到可用数据集,获取方法可以在浏览器和Node.js执行。Tf.dada.csv的API同样允许我们在请求中添加参数。
const url = 'http://path/to/your/private.csv'
const requestInfo = new Request(url);
const API_KEY = 'abcdef123456789'
requestInfo.headers.append('Authorization', API_KEY);
const myDataset = tf.data.csv(requestInfo);
# 6.4.2使用tf.data.webcam访问视频数据
TensorFlow.js项目最令人兴奋的应用之一是训练ML模型并将其应用于移动设备上。使用移动车载加速计进行运动识别?使用车载麦克风进行声音或语音识别?使用车载摄像头进行视觉辅助?我们才刚刚开始。 在第5章中,我们探讨了在迁移学习的背景下使用网络摄像头和麦克风。我们看到了如何使用相机来控制吃豆人的游戏,我们使用麦克风来微调一个语音识别系统。虽然并不是所有的都可以使用一个方便的API进行调用,但tf.data确实有一个简单易用的API来处理网络摄像头。让我们来探索它是如何工作的,以及如何使用它从训练过的模型中进行预测。 有了这个tf.data API,创建一个数据集非常简单,它可以从网络摄像头生成一个图像流。清单6.14展示了一个基本示例。我们首先注意到的是对tf.data.webcam()的调用。如果在Node.js环境中调用此API,或者没有可用的网络摄像头,那么将抛出一个异常,指示错误的来源。浏览器在打开网络摄像头之前需要得到用户的许可。如果被拒绝,构造函数也将引发异常。
# 清单6.14使用tf.data.webcam和HTML元素创建基本的网络摄像头数据集
const videoElement = document.createElement('video');
videoElement.width = 100;
videoElement.height = 100;
const webcam = await tf.data.webcam(videoElement);
const img = await webcam.capture();
img.print();
webcam.stop();
创建摄像机构造函数时,必须知道要生成的张量的形状。有两种方法可以实现。第一种方法,如清单6.14所示,使用提供的HTML元素的形状。如果需要改变形状,或者不显示视频,则可以通过配置对象提供所需的形状,如清单6.15所示。注意,提供的HTML元素参数是未定义的,这意味着API将在DOM中创建一个隐藏的元素来充当视频。
# 清单6.15使用配置对象创建基本网络摄像头数据集
const videoElement = undefined;
const webcamConfig = {facingMode: 'user', resizeWidth: 100, resizeHeight: 100};
const webcam = await tf.data.webcam(videoElement, webcamConfig);
也可以使用配置对象裁剪视频流的部分并调整其大小。通过使用HTML元素和配置对象,API允许调用者指定要裁剪的位置和所需的输出大小。请参见清单6.16中的示例,该示例选择一个正方形视频的矩形部分,然后减小大小以适合一个小模型。
# 清单6.16从网络摄像机裁剪和调整数据大小
const videoElement = document.createElement('video');
videoElement.width = 300;
videoElement.height = 300;
const webcamConfig = {
resizeWidth: 150,
resizeHeight: 100,
centerCrop: true
};
const webcam = await tf.data.webcam(videoElement, webcamConfig);
无论它们的绘制速度有多快或有多慢,都将按顺序生成一行一行的数据集。可以从网络摄像机中提取想要的很多的样本。API调用方在处理完流后必须显式地告诉流结束。 使用capture()方法从网络摄像机迭代器访问数据,该方法返回表示最近帧的张量。API用户应该在其ML工作中使用这个张量,但要防止内存泄漏。由于网络摄像头数据的异步处理涉及到复杂的问题,最好直接对捕获的帧应用必要的预处理功能,而不是使用tf.data提供的deferred map()功能。 也就是说,不是使用data.map处理数据,
// No:
let webcam = await tfd.webcam(myElement)
webcam = webcam.map(myProcessingFunction);
const imgTensor = webcam.capture();
// use imgTensor here.
tf.dispose(imgTensor)
将函数直接应用于图像。
// Yes:
let webcam = await tfd.webcam(myElement);
const imgTensor = myPreprocessingFunction(webcam.capture());
// use imgTensor here.
tf.dispose(imgTensor)
forEach() 和toArray()方法不应在网络摄像机迭代器上使用。为了处理来自设备的长帧序列,tf.data.webcam API的用户应该自定义自己的循环,例如,tf.nextFrame()以及以合理的帧速率调用capture()。原因是,如果您要调用网络摄像头的forEach(),那么框架将以浏览器的JavaScript引擎请求的速度绘制帧。这通常会比设备的帧速率更快地创建张量,从而导致重复帧和浪费计算。出于类似的原因,不应将网络摄像机迭代器作为参数传递给该 model.fit()方法。 清单6.17显示了我们在第5章中看到的(Pac Man)示例中的简化预测循环。请注意,只要isPredicting为true(由ui元素控制),外部循环将继续。在内部,循环的速率由调用tf.nextFrame()控制,该调用被固定到UI的刷新速率。
# 清单6.17在预测循环中使用tf.data.webcam(来自tf js-examples/webcam transfer learning/index.js)
```js
async function getImage() { return (await webcam.capture()) .expandDims(0) .toFloat() .div(tf.scalar(127)) .sub(tf.scalar(1));
while (isPredicting) { const img = await getImage();
const predictedClass = tf.tidy(() => { #Capture the frame from the webcam.
// Process the image and make predictions...
...
await tf.nextFrame();
}
使用网络摄像头时,在预测之前,通常最好先绘制、处理和丢弃图像。首先,通过模型传递图像可以确保相关的模型权重已加载到GPU中,从而防止启动时出现任何断断续续的缓慢情况。其次,这给了摄像头硬件时间来预热并开始发送实际帧。根据硬件的不同,有时网络摄像头会在设备通电时发送空白帧。请参见清单6.18中的一个片段,该片段显示了如何在webcam transfer学习示例中完成此操作。
###### 清单6.18从tf.data.webcam()创建视频数据集
```js
async function init() {
try {
webcam = await tfd.webcam(document.getElementById('webcam'));
} catch (e) {
console.log(e);
document.getElementById('no-webcam').style.display = 'block';
}
truncatedMobileNet = await loadTruncatedMobileNet();
ui.init();
// Warm up the model. This uploads weights to the GPU and compiles the WebGL
// programs so the first time we collect data from the webcam it will be
// quick.
const screenShot = await webcam.capture();
truncatedMobileNet.predict(screenShot.expandDims(0));
screenShot.dispose();
}
# 6.4.3使用tf.data.microphone访问音频数据
除了图像数据,tf.data还包括从设备麦克风收集音频数据进行处理。与网络摄像头API类似,麦克风api创建了一个延迟迭代器,允许调用者根据需要请求帧,并将其整齐地打包为适合直接使用到模型中的张量。这里主要是收集用于预测的帧。虽然在技术上可以使用这个API生成一个训练流,但是将它与标签压缩在一起将是一个挑战。 清单6.19展示了一个如何使用tf.data.microphone API收集一秒音频数据的示例。请注意,执行此代码将触发浏览器请求用户授予对麦克风的访问权限。
# 清单6.19使用tf.data.microphone api收集一秒钟的音频数据
const mic = await tf.data.microphone({
fftSize: 1024,
columnTruncateLength: 232,
numFramesPerSpectrogram: 43,
sampleRateHz: 44100,
smoothingTimeConstant: 0,
includeSpectrogram: true,
includeWaveform: true
});
const audioData = await mic.capture();
const spectrogramTensor = audioData.spectrogram;
const waveformTensor = audioData.waveform;
mic.stop();
麦克风包括许多可配置参数,使用户可以精细控制如何将快速傅立叶变换(FFT)应用于音频数据。每个频谱图可以有更多或更少的音频数据帧,或者用户可能只获取特定频率范围。上述字段具有以下含义:
- 采样频率:44100
- 麦克风波形的采样率。必须正好是44100或48000,并且必须与设备本身指定的速率匹配。如果指定的值与设备提供的值不匹配,它将引发错误。
- fftSize:1024
- 控制用于计算音频的每个非重叠帧的采样数。
- 必须是介于16和8192之间的两个值。1024表示在大约1024个样本范围内计算频带的值。
- 注意,最高可测量频率等于采样率的一半,或约22kHZ
- 列截断长度:232
- 控制保留的频率大小。默认情况下,每个音频帧包含fftsize,在我们的例子中是1024,从0到最大(22kHZ)的整个频谱。然而,我们通常只对较低的频率感兴趣。人类的语音一般只有5千赫兹,因此我们只把数据中代表0到5千赫兹的部分。
- 232 = (5kHz / 22kHz) * 1024 numFramesPerSpectrogram: 43
- 在音频样本上计算FFT以创建频谱图。返回的光谱图的形状需要是[numFramesPerSpectrogram, fftSize, 1]或者 [43, 232, 1]
- 每帧的持续时间等于sampleRate / fftSize。在我们的例子中,44kHz * 1024大约是0.023秒。
- 帧之间没有延迟,所以整个谱图持续时间43 * 0.023 = 0.98大约一秒钟。
- smoothingTimeConstant: 0
- 前一帧的数据与此帧混合的程度。必须介于0和1之间。
- includeSpectogram: True
- includeSpectogram为true,谱图将被计算并作为张量提供。如果应用程序不需要计算谱图,则将此设置为false。
- includeWaveform: True
- includeWaveform为True,波形将保持并可用作张量。如果调用者不需要波形,则可以将其设置为false。请注意,includeSpectogram和includeWaveform中至少有一个必须为真。如果它们都是假的,那就是错误。这两个选项中只有一个是必需的。
- 与视频流类似,音频流有时需要一些时间才能启动,而来自设备的数据可能在开始时是无意义的。通常会遇到零和无穷大。最好的解决方案是通过丢弃前几个样本,使麦克风“预热”一小段时间,直到数据不再损坏。通常200毫秒的数据足以开始获取干净的样本。