与我交流

# 6.3 使用model.fitDataset的训练模型
我们已经看到dataset API允许我们进行一些优雅的数据操作,但是tf.data API的主要目的是简化将数据连接到我们的模型以进行训练和评估。tf.data对我们有什么帮助?
从第二章开始,每当我们想训练一个模型时,我们就使用model.fit() API。回想一下,至少model.fit()需要两个必要参数,即xs和ys。提醒一下,xs变量必须是表示输入示例集合的张量。ys变量必须绑定到表示相应输出目标集合的张量。例如,在前一章的清单5.11中,我们使用如下调用对合成对象检测模型进行了训练和微调:
model.fit(images, targets, modelFitArgs)
其中默认情况下images是一个4阶形状张量[2000,224,224,3],表示2000个图像的集合。配置对象modelFitArgs指定了优化器的批处理大小,默认为128。
如果数据量还不够,我们想用更大的数据集来训练呢?在这种情况下,一是加载更大的数组,看看它是否有效。但是,在某个时刻,TensorFlow.js将耗尽内存并指示它无法为训练数据分配存储空间。二是我们将数据分块上传到GPU,并对每个块进行model.fit(),在训练数据的片段上训练我们的模型,只要它准备好了就迭代地进行。如果我们想执行多个epoch,我们需要返回并以某种顺序(可能是无序的)重新下载我们的块。这种方式不仅麻烦且容易出错,而且还会干扰TensorFlow对epoch计数和度量。
TensorFlow.js使用model.fitDataset()这个API为我们提供了一个更方便的方法。
model.fitDataset(dataset, modelFitDatasetArgs)
model.fitDataset()接受数据集作为其第一个参数,但数据集必须满足特定规则才能工作。具体来说,数据集必须生成具有两个属性的对象。第一个属性名为“xs”,其值类型为Tensor,表示一批示例的特征,类似于model.fit的xs参数,但数据集一次生成一批元素,而不是一次生成整个数组。第二个必需属性名为“ys”,包含相应的目标张量[99]。
相比model.fit,model. fitDataset提供了一些优势。最重要的是,我们不需要编写代码来管理和编排数据集片段的下载,这是按需的流方式更加高效。数据集中内置的缓存结构允许预取需要的数据,有效地利用我们的计算资源。这个API也允许在GPU上进行更大数据集的训练。事实上,我们可以训练的数据集的大小只受时间的限制,因为只要我们能够获得新的训练示例,我们就可以继续训练。此行为在tfjs-examples库中的data-generator示例中进行了证明。
在这个例子中,我们将训练一个模型来学习如何估计赢得一个简单的游戏的可能性。与往常一样,您可以使用以下命令并运行演示:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/data-generator
yarn
yarn watch
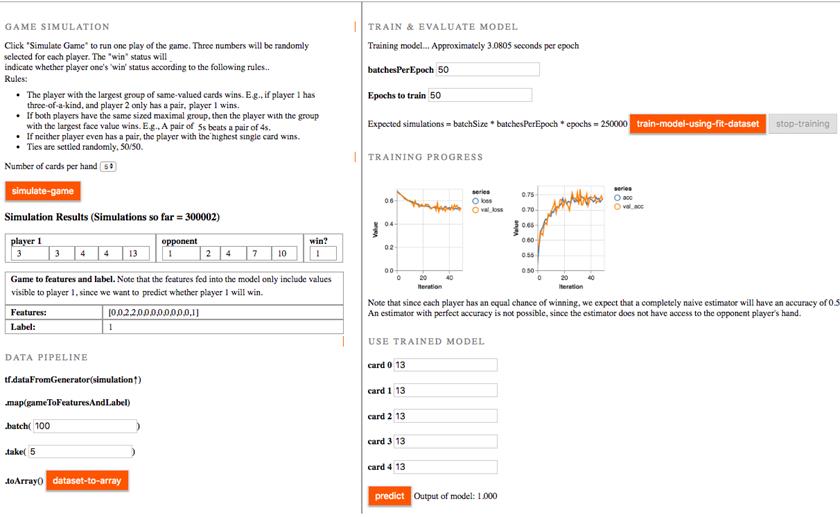
# 图6.1数据生成器示例的用户界面。游戏规则和运行模拟的按钮在左上角。下面显示了生成的特征和数据管道。运行“数据集到数组”按钮将运行链式操作,将模拟游戏、生成特征、批处理样本、获取N个此类批处理、将它们转换为数组并打印。在右上角,提供了训练模型的可编辑参数。当用户训练模型时,model.fitDataset将提取样本。损失和精度曲线打印在下面。在右下角,用户可以输入玩家1的牌,然后根据模型进行预测。
 这里使用的游戏是一个简化的纸牌游戏,有点像扑克。两个玩家都有N张牌,其中N是正整数,每张牌由1到13之间的随机整数表示。游戏规则如下:
• 同值牌最多的玩家获胜。 比如,如果玩家1有三张同值纸牌,而玩家2只有一对,则玩家1获胜。
• 如果两个玩家拥有相同大小的队牌,那么拥有最大面值组的玩家获胜。比如, 一对5胜过一对4。
• 如果两个玩家都没有一对牌,那么单张牌最高的玩家获胜。
这里使用的游戏是一个简化的纸牌游戏,有点像扑克。两个玩家都有N张牌,其中N是正整数,每张牌由1到13之间的随机整数表示。游戏规则如下:
• 同值牌最多的玩家获胜。 比如,如果玩家1有三张同值纸牌,而玩家2只有一对,则玩家1获胜。
• 如果两个玩家拥有相同大小的队牌,那么拥有最大面值组的玩家获胜。比如, 一对5胜过一对4。
• 如果两个玩家都没有一对牌,那么单张牌最高的玩家获胜。
每个玩家都有平等的获胜机会。如果我们对我们的牌一无所知,我们应该只能猜测我们有一半的概率会赢。我们建立并训练一个以玩家1的牌作为输入的模型,并预测玩家是否会赢。在上面的屏幕截图中,在对大约250000个示例(50个epoch乘以50batch/epoch*100个示例/batch)进行训练后,我们能够获得大约75%的准确性。在这个模拟中,每次使用五张卡片,也达到了类似的精度。更高的准确度是可以通过更大批量运行来实现的。但即使是在75%准确度的情况下,我们的智能玩家在估计他们获胜的可能性方面也比普通玩家有着显著的优势。 如果使用model.fit()执行此操作,则需要创建并存储250000个示例的张量,表示输入特征。本例中的数据非常小,每个实例只需要10字符的浮点,但对于我们在上一章中的对象检测任务,250000个示例需要150GB的GPU内存,远远超过了2019年大多数浏览器中可用的内存。 让我们深入了解一下这个例子的相关部分。首先让我们看看如何生成数据集。清单6.7中的代码类似于上面清单6.3中的骰子滚动生成器数据集,因为我们存储了更多的信息,所以复杂性要高一些。
# 清单6.7为我们的纸牌游戏建立一个tf.data.Dataset。从tfjs examples/data generator/index.js中简化
import * as game from './game';
let numSimulationsSoFar = 0;
function runOneGamePlay() { //
const player1Hand = game.randomHand();
const player2Hand = game.randomHand();
const player1Win = game.compareHands(player1Hand, player2Hand);
numSimulationsSoFar++;
return {player1Hand, player2Hand, player1Win};
}
function* gameGeneratorFunction() {
while (true) {
yield runOneGamePlay();
}
}
export const GAME_GENERATOR_DATASET = tf.data.generator(gameGeneratorFunction);
await GAME_GENERATOR_DATASET.take(1).forEach(e => console.log(e));
一旦我们将基本的生成器数据集连接到游戏逻辑,我们希望以一种对我们的学习任务有意义的方式格式化数据。具体来说,我们的任务是尝试从玩家1中预测玩家1取胜的能力。为了做到这一点,我们需要使我们的数据集返回以这样的形式[batchOfFeatures,batchOfTargets],其中的特征是从玩家1纸牌中计算出来的。
# 清单6.8建立玩家特征的数据集。从tfjs examples/data generator/index.js中简化
function gameToFeaturesAndLabel(gameState) {
return tf.tidy(() => {
const player1Hand = tf.tensor1d(gameState.player1Hand, 'int32');
const handOneHot = tf.oneHot(
tf.sub(player1Hand, tf.scalar(1, 'int32')),
game.GAME_STATE.max_card_value);
const features = tf.sum(handOneHot, 0);
const label = tf.tensor1d([gameState.player1Win]);
return {xs: features, ys: label};
});
}
let BATCH_SIZE = 50;
export const TRAINING_DATASET = GAME_GENERATOR_DATASET.map(gameToFeaturesAndLabel)
.batch(BATCH_SIZE);
await TRAINING_DATASET.take(1).forEach(e => console.log([e.shape, e.shape]));
现在我们有了一个格式正确的数据集,可以使用清单6.9所示的方法model.fitDataset()连接到我们的模型。
# 清单6.9在数据集上建立和训练模型。从tfjs examples/data generator/index.js中简化
#Construct model.
model = tf.sequential();
model.add(tf.layers.dense({
inputShape: [game.GAME_STATE.max_card_value],
units: 20,
activation: 'relu'
}));
model.add(tf.layers.dense({units: 20, activation: 'relu'}));
model.add(tf.layers.dense({units: 1, activation: 'sigmoid'}));
// Train model
await model.fitDataset(TRAINING_DATASET, {
batchesPerEpoch: ui.getBatchesPerEpoch(),
epochs: ui.getEpochsToTrain(),
validationData: TRAINING_DATASET,
validationBatches: 10,
callbacks: {
onEpochEnd: async (epoch, logs) => {
tfvis.show.history(
ui.lossContainerElement, trainLogs, ['loss', 'val_loss'])
tfvis.show.history(
ui.accuracyContainerElement, trainLogs, ['acc', 'val_acc'],
{zoomToFitAccuracy: true})
},
}
}
如清单6.9所示,将模型拟合到数据集就像将模型拟合到一对X,y张量一样简单。只要我们的数据集以正确的格式生成张量值,一切都会正常工作,并且我们可以从远程源获得流式数据,而不需要自己管理编排。除了传入数据集不是张量对之外,配置对象中还有一些差异值得讨论:
batchesPerEpoch:正如我们在上面的代码列表中看到的,model.fitDataset()的配置接受一个可选字段,用于指定构成epoch的批数。当我们将整个数据交给model.fit()时,很容易计算出整个数据集中有多少个示例。就是data.shape [0]!当使用fitDataset()时,我们可以通过以下两种方式之一告诉TensorFlow.js何时结束。第一种方法是使用配置字段,fitDataset()将在多个批处理之后执行onEpochEnd和onEpochStart回调。第二种方法是让数据集本身结束,作为数据集耗尽的信号。在清单6.7中,我们可以更改while (true) { … } 到 for (let i = 0; i<ui.getBatchesPerEpoch(); i++) { … }来模仿这种行为。 validationData:使用fitDataset()时,validationData也可以是一个数据集,也可以是张量。对于返回元素的格式,验证数据集需要满足与训练数据集相同的规范。 validationBatches:如果您的验证数据来自一个数据集,则需要告诉TensorFlow.js要从该数据集中提取多少样本才能构成一个完整的评估。如果未指定任何值,则TensorFlow.js将继续从数据集中绘制,直到返回完成信号。在上面的代码中,这永远不会发生,程序将挂起。 其余配置与model.fit()API的配置相同,因此无需更改。